



Containerization has become an essential part of modern business operations. By isolating applications and services within containers, businesses achieve greater efficiency, scalability, and flexibility.
In this article, we’ll discuss what containerization is and the role of Docker in containerization. We’ll also look at the differences between virtualization and containerization.
What are containers?
A container is a package containing all the necessary components required to run an application. It makes it super easy to move your app from one environment to another. You don't have to stress about compatibility issues or anything like that. For instance, a developer can quickly move the app from their laptop to a production server without any hassle.
Imagine you're developing a web app with Python. You're using a particular version of Python and a set of libraries to run it on your laptop. When it's time to deploy it on a production server, all you need to do is take the container from your laptop and move it to the server. The container bundles all the dependencies, so you can be sure that the app will run the same way on the server as it did on your laptop. This holds true even if the server has different libraries installed or runs a different version of the operating system.
This is a huge advantage over traditional approaches to software deployment. In particular, it eliminates the headache of compatibility issues. With containers, you can rest assured that the application will function as intended, regardless of where you deploy it.
Read more about containers:
 Paul Andrew Arboleda
Paul Andrew Arboleda
Why We Need Containerization?
We’re now going to look at a high-level overview of why you need containerization and what it can do for you. Let me start by sharing how I got introduced to Docker. In one of my previous projects, I had this requirement to set up an end-to-end stack including various different technologies, like a web server using node js, databases such as MongoDB, a messaging system like Redis, and an orchestration tool like Ansible.
We had a lot of issues developing this application with all these different components. First, we had to address compatibility with the underlying operating system. We had to ensure that all these different services were compatible with the version of the operating system we were planning to use.

There were certain versions of these services that were not compatible with the OS. We had to go back and look for another OS that was compatible with all these different services. Secondly, we had to check the compatibility between the services and the libraries and dependencies on the OS. We had issues where one service required one version of a dependent library, whereas another service required another version.
Try the Docker Basic Commands Lab for free

The architecture of our application changed over time - we had to upgrade to newer versions of these components or change the database, etc. And every time something changed, we had to go through the same process of checking compatibility between these various components and the underlying infrastructure.
This compatibility matrix issue is usually referred to as the matrix from hell.
Next, every time we had a new developer on board, we found it really difficult to set up a new environment; the new developers had to follow a large set of instructions and run hundreds of commands to finally set up their environment. They had to make sure they were using the right operating system and the right versions of each of these components. And each developer had to set all that up by himself each time.
We also had different development tests and production environments. Sometimes one developer would be comfortable using one OS, and the developers were be using another one. And so, we couldn’t guarantee that the application we were building would run the same way in different environments. All of this made our life really difficult.
Solution: I needed something that could help us with the compatibility issue. Something that would allow us to modify or change these components without affecting the other components and even modify the underlying operating system as required. And that search landed me on containerization.
More specifically, Docker containerization.
What is Docker?
Docker is an open-source containerization tool. It allows developers to package their applications and dependencies into containers, which can be easily deployed across different environments.
Let's see how Docker solved our problem.
With Docker, I was able to run each component in a separate container with its own libraries and its own dependencies, all on the same VM and the OS but within separate environments or containers. We just had to build the Docker configuration once, and all our developers could now get started with a simple Docker run command, irrespective of the operating system they run. All they needed to do was to make sure they had Docker installed on their systems.
Here is the graphical representation of the project after containerizing the applications with Docker.
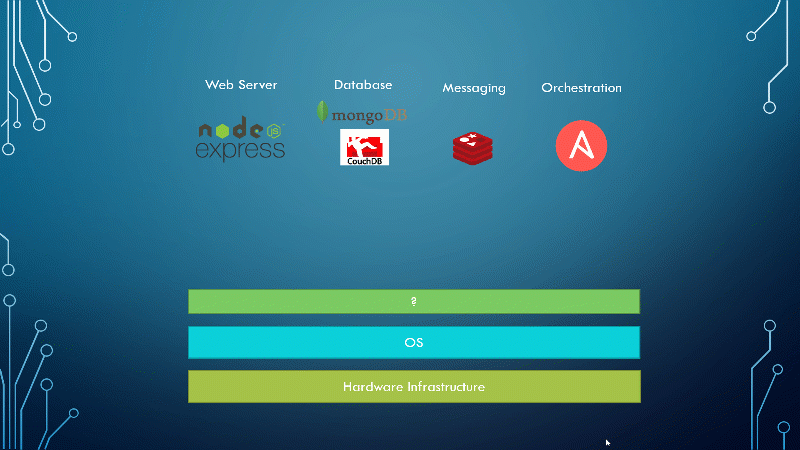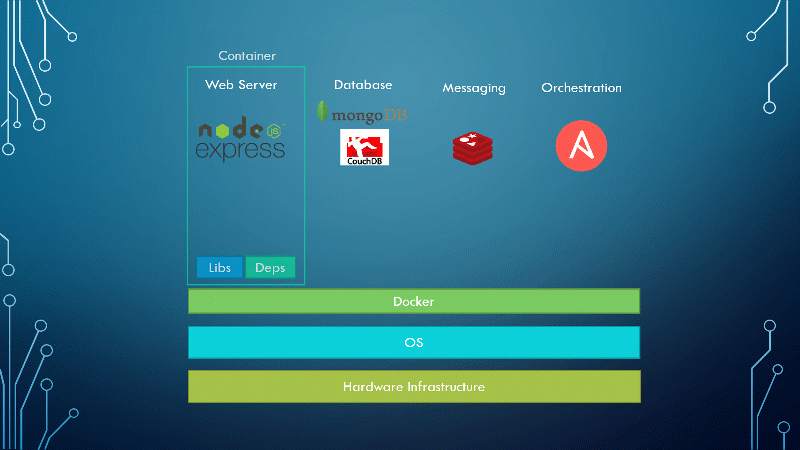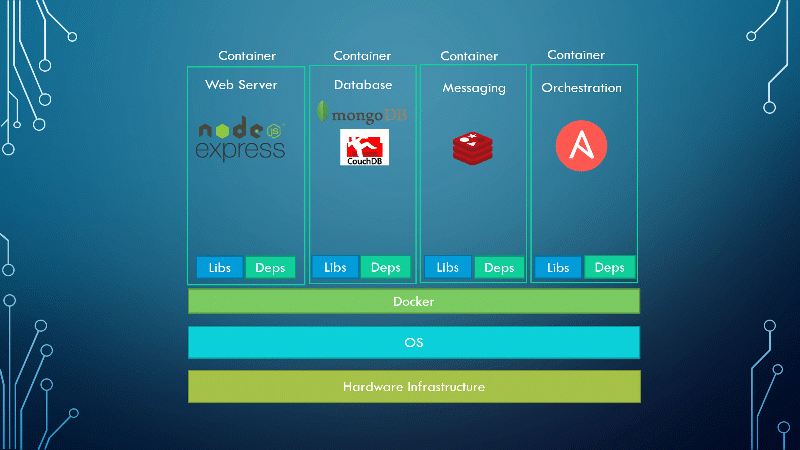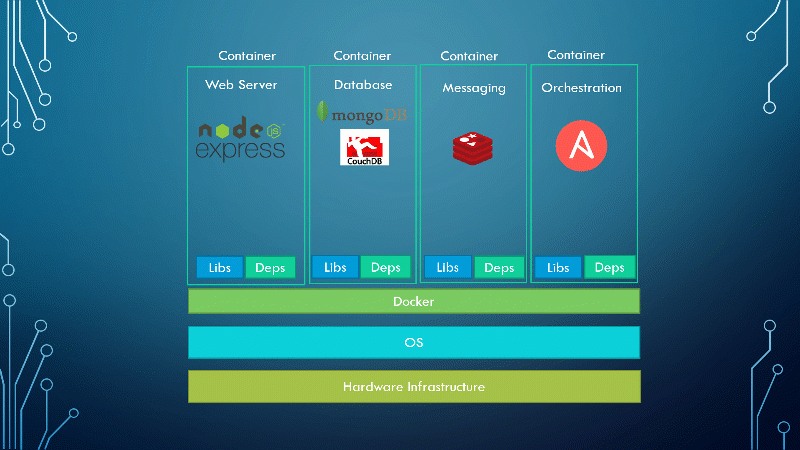
Containers existed way before Docker. But Docker made everything easier with a rather simple approach. Not to say that it was simple for the developers to write this utility. But it was simple for users to manage containers with it.
Docker gives us a way to do everything we want with containers, with a single tool, without needing to download additional programs. It simplifies our user experience.
How does Docker work?
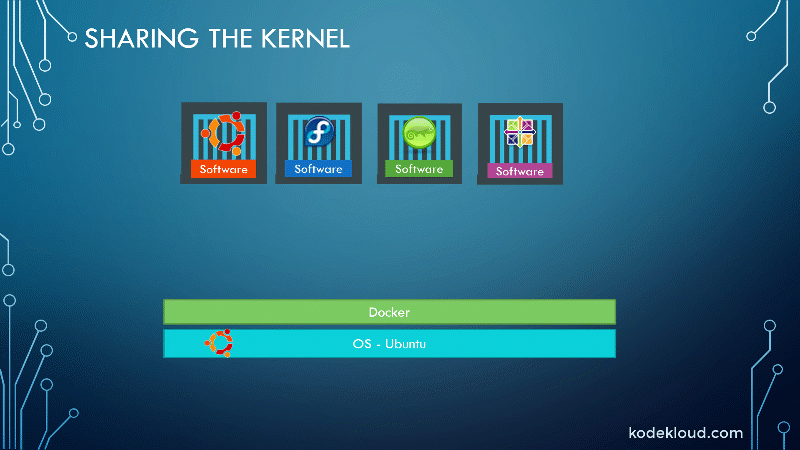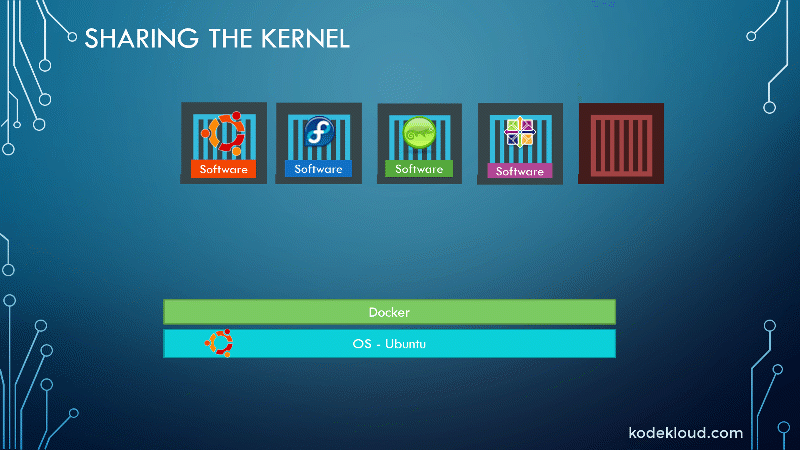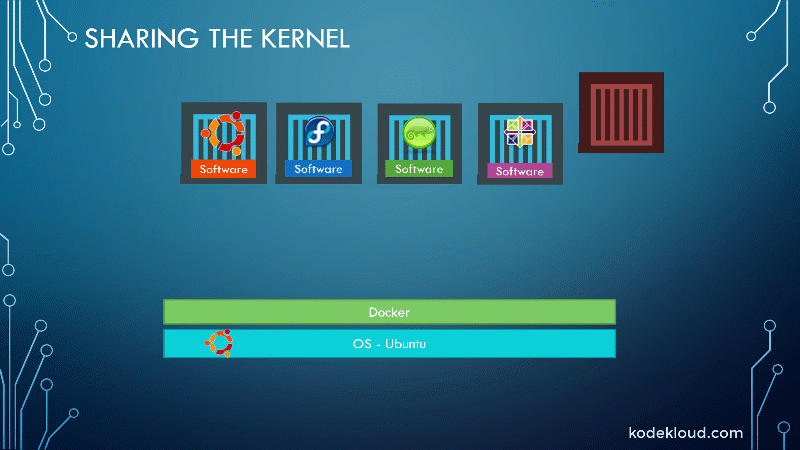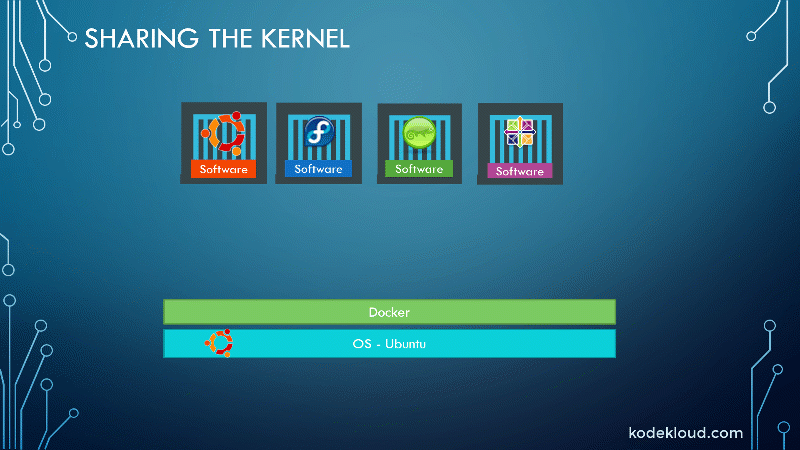
To understand how Docker works, let us first revisit some basic concepts of operating systems. If you look at operating systems like Ubuntu, Fedora, CentOS, etc., they all consist of two things, an OS kernel and a set of software. The operating system kernel is responsible for interacting with the underlying hardware, while the OS kernel remains the same, which is Linux in this case; it’s the software above it that makes these operating systems different.
The software may consist of different user interface drivers, compilers, file managers, developer tools, etc. This leaves us with a common Linux kernel shared across all operating systems and some custom software that differentiates operating systems from each other.
Docker containers share the underlying kernel. What does that actually mean, sharing the kernel?

Let’s say we have a system with an Ubuntu OS with Docker installed on it. Docker can run any flavor of OS on top of it as long as they’re all based on the same kernel, in this case, Linux. If the underlying operating system is Ubuntu, Docker can run a container based on another distribution like Debian, Fedora, Susi, or CentOS. Each Docker container only has the additional software that we just talked about previously, i.e., the software that makes these operating systems different.
And Docker utilizes the underlying kernel of the Docker host, which works with all the operating systems above. So, if an OS does not share the same kernel, for instance, Windows, you won’t be able to run a Windows-based container on a Docker host with Linux OS on it. For that, you would require Docker on a Windows Server.
You might be thinking, isn’t that a disadvantage then? Not being able to run another kernel on the OS? The answer is no. Because, unlike hypervisors, Docker is not meant to virtualize and run different operating systems and kernels on the same hardware. The main purpose of Docker is to containerize applications, ship them, and run them.
Virtual Machines vs. Containers
So that brings us to the differences between virtual machines and containers, something that we tend to do, especially those from a virtualization background. As you can see on the right, in the case of Docker, we have the underlying hardware infrastructure, then the operating system and Docker installed on the OS. Docker can then manage the containers that run with libraries and dependencies alone.

In the case of a virtual machine, we have the OS on the underlying hardware, then the hypervisor like ESX or virtualization of some kind, and then the virtual machines. As you can see, each virtual machine has its own operating system inside it. Then the dependencies, and then the application.
This overhead causes higher utilization of underlying resources as there are multiple virtual operating systems and kernels running. The virtual machines also consume higher disk space as each VM is heavy and it’s usually gigabytes in size, whereas Docker containers are lightweight and they’re usually megabytes in size. This allows Docker containers to boot up faster, usually in a matter of seconds, whereas virtual machines, as we know, take minutes to boot up as it needs to boot up the entire operating system.
It is also important to note that Docker has less isolation as more resources are shared between containers like the kernel, whereas VMs have complete isolation from each other. Since VMs, don’t rely on the underlying operating system or kernel. You can have different types of operating systems, such as Linux based or Windows-based, on the same hypervisor. This is not possible on a single Docker host. These are some differences between the two.
There are a lot of containerized versions of applications readily available today. So most organizations have their products containerized and available in a public Docker registry called Docker Hub already. For instance, you can find official images of the most commonly used operating systems, databases, and other services.
Once you identify the image you need, you can pull it to your Docker host. Bringing up an application stack is as easy as running a Docker run command with the name of the image.

As we have seen before, a lot of products have been Dockerized already. If you cannot find what you’re looking for, you could create an image and push it to the Docker Hub repository, making it available to the public.
What is a Docker Image?
Essentially, a Docker image is a static file that contains everything needed to run an application, including the application code, libraries, dependencies, and the runtime environment. It's like a snapshot of a container that, when executed, creates a Docker container.
A Docker image is composed of multiple layers stacked on top of each other. Each layer represents a specific modification to the file system (inside the container), such as adding a new file or modifying an existing one. Once a layer is created, it becomes immutable, meaning it can't be changed. The layers of a Docker image are stored in the Docker engine's cache, which ensures the efficient creation of Docker images.
Benefits of using Docker with DevOps
If you look at it, traditionally, developers developed applications. Then they hand it over to the Ops team to deploy and manage it in production environments. They do that by providing a set of instructions, such as information about how the host must be set up, what prerequisites are to be installed on the host, how the dependencies are to be configured, etc.
The Ops team uses this guide to set up the application. Since the Ops team does not develop the application, they struggle with setting it up. When they hit an issue, they work with the developers to resolve it.
With Docker, developers hand over to the operations team an application - packaged as an image - that can run seamlessly run on any environment (testing, staging, or production). It guarantees that if a feature functions in the development environment, it will also work in the production and staging environments. So the Ops team can now simply use the image to deploy the application.
Docker eliminates friction between the two teams and eases the work of automating steps such as testing, staging, and deployment. This helps accelerate application development and improves the overall performance of applications in a production environment.
ENROLL in our FREE Docker for Absolute Beginners Course to learn more about creating and running containers.

Conclusion
You've learned why we containerize applications and how this impacts overall efficiency. You've also learned the role of Docker in containerization and DevOps as a whole.
Watch this video to get more practical Docker lessons.
More on Docker containers:














Discussion