



Kubernetes services are an essential component of any Kubernetes deployment. They allow you to expose your application to other parts of your cluster and the outside world by providing a stable IP and DNS name. With Kubernetes services, you can easily scale your application, perform load balancing, and even define routing based on a set of rules.
This blog focuses on Ingress, a Kubernetes tool for managing access to a cluster's services.
What is Kubernetes Ingress?
Kubernetes ingress is a powerful tool for managing external access to your Kubernetes services. It acts as a layer between your services and the outside world, providing load balancing, SSL termination, and routing based on your defined rules. With Kubernetes ingress, you can easily expose your services to the internet while maintaining granular control over who has access to them.
Learn more services from this blog: Kubernetes Services: Definitions & Examples (2024)
Although the ingress is just another way of exposing services outside the cluster, it is not itself considered a service type. It is a separate API object type.
Try the Kubernetes Services Lab for free

Try the Docker Run Lab for free
How Kubernetes Ingress Works
The way it works at a high level is that you first deploy what is called an Ingress controller. This controller is the actual engine that executes the rules of the ingress by translating them and routing the traffic accordingly.
An ingress controller is like a load balancer which has some forwarding rules. And these rules are passed to this load balancer through an ingress object. Yes, we need both an ingress controller and an ingress resource/object in Kubernetes. Later on, we'll see why.
There are a couple of ingress controller implementations out there, but the most popular are Nginx and HAProxy.
Now let’s get into the steps of how this works.
As we mentioned, the first step to enable ingress routing is to install the ingress controller. It is typically deployed as a pod inside the cluster through a deployment or a daemonset object. You can find an example of installing an Nginx ingress controller here.
Some ingress controllers also support being deployed outside the cluster, but this requires additional configuration for enabling routing through BGP and BIRD. You can check this article for more information.
But for now, let’s stick with the traditional example of the inside-cluster deployment.
After the controller has been deployed, it is time to start creating the ingress resource. This ingress resource will update the controller with the rules to be applied to the traffic. It is created and configured using a manifest file like any other Kubernetes object.
Example of an ingress manifest:
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: ingress-wildcard-host
spec:
rules:
- host: "foo.bar.com"
http:
paths:
- pathType: Prefix
path: "/bar"
backend:
service:
name: service1
port:
number: 80
- host: "*.foo.com"
http:
paths:
- pathType: Prefix
path: "/foo"
backend:
service:
name: service2
port:
number: 80(source)
Inside the ingress, we can define:
- The host where the rules are applied, e.g., for "example.com" host or "other-example.org"
- A specific path, e.g., "example.com/path/to/shop"
- Whether to use HTTP or HTTPS.
- The service and the port to route the traffic to when it matches these rules.
Here, we want traffic destined to foo.bar.com/bar to be routed to the service with the name service1 on port 80
So when applying this ingress, if a request hits the ingress controller with destination host foo.bar.com and path /bar, the controller will forward this traffic to the service running on the cluster with the name service1 on port 80. Then it’s the service that forwards this traffic to the pods behind it, as usual.
You can see now how much flexibility the ingress rules have. Instead of just relying on an IP and port to load balance the traffic, it can load balance based on content in the HTTP header. We can just create smarter, more advanced load-balancing rules.
The ingress controller makes it possible to have dozens of services running inside your cluster, and you redirect the traffic to each one using only one external-facing IP.
But wait! Didn’t we mention previously that the ingress controller pods are deployed inside the cluster? So, how does the traffic reach the ingress controller in the first place?
Well, simply through a LoadBalancer service. Read more about how a Loadbalancer does this here.
The idea is that you want to expose your ingress controller itself to the outside network. This way, it can receive external traffic. But this time, the difference is that you only expose a single service through the LoadBalancer, which is the ingress controller service. Then, it’s up to this service to route the traffic to other backend services in the cluster.
This way, you can use a single load balancer IP to forward traffic to all your services. And it’s the responsibility of the ingress controller to decide where to direct traffic. Based on its rules and how the content matches those rules, it will decide which service it should forward requests to.
So the Path now is:
Client 🡪 LoadBalancer 🡪 Ingress controller 🡪 Other services 🡪 Pod
Are you looking to polish your Kubernetes skills? Check out this Kubernetes course from KodeKloud:

.png)
Deploying an Ingress Controller
Assume you have two services running in your cluster. The first service handles traffic for app.test.com, and the second service handles traffic for app.prod.com. Both services receive traffic on port 8080 to forward it to the pods.
Configuring Ingress Controller Rules
Now, you want to expose these services outside the cluster to allow external clients to reach them. So you are about to configure an ingress.
First, you deploy an ingress controller into your cluster, which is basically a set of pods as part of a deployment. These pods also have their own cluster service - let’s call it ingress-service.
Now, you start creating your ingress object. You add two rules inside this ingress.
- One to forward the traffic destined for app.test.com to service 1 on port 8080
- One to forward traffic destined for app.prod.com to service 2 on port 8080.
The ingress controller will continuously monitor the cluster for newly created or updated ingress objects. Once it finds an ingress rule, it will configure it and start applying it to the traffic. In our example, the ingress controller will detect the ingress rules created for the app.test.com and app.prod.com hosts and start applying them.
So whenever it sees traffic with a destination host app.test.com, it will redirect it to service 1 on port 8080. And the same applies to service 2 with host app.prod.com. The remaining part now is that you want your ingress controller itself to be able to receive traffic from external clients to match it against these rules.
Configuring a LoadBalancer
Now, you need to create a LoadBalancer service that receives traffic on port 80 and forwards it to the ingress-service. What happens now is that the cloud provider will provision a new external load balancer with a public IP address. Then, it adds a rule to it for forwarding traffic to the ingress-service.
Summary:
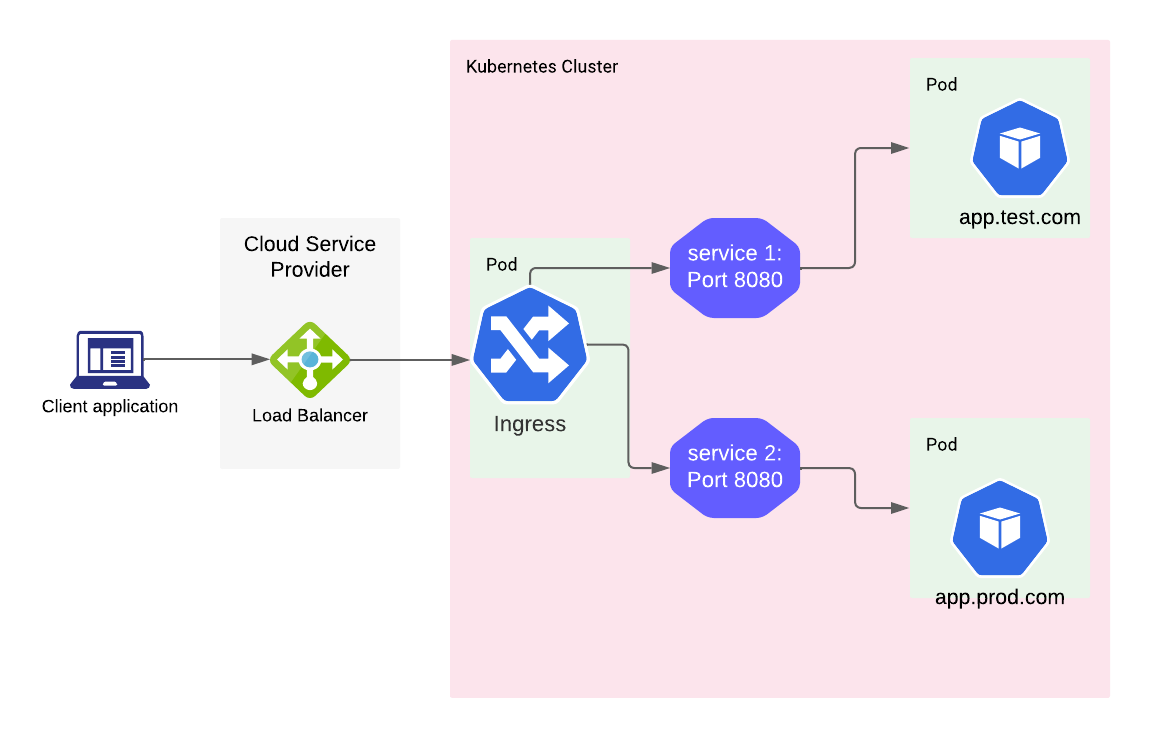
When traffic reaches the load balancer at the <Loadbalancer-IP>:80, it will be redirected to the ingress service. Next, the ingress controller will check the contents of the traffic and apply a matching rule, if found, and forward it to service 1 or service 2. Finally, this traffic reaches the Pods.
More on Kubernetes:
- Top 15 DevOps Automation Tools You Should Learn in 2024
- 4 DevOps Metrics You Need To Track Quality And Performance
- 10 Essential DevOps Tools You Should Learn in 2024
- 17 DevOps Monitoring Tools to Learn in 2024
- How to Use Kubectl Config Set-Context
- Kube-Proxy: What Is It and How It Works
- How to Deploy Postgres on Kubernetes for a Scalable Web Application














Discussion