



Highlights
- The Core Mechanism: Understanding how Git works under the hood transforms you from a casual user into a power user who can confidently manage code history.
- Three-Stage Architecture: Mastering the Git basics means understanding the flow between the working directory, the staging area, and the local repository.
- Inner Workings: Peeking into Git internals reveals how it stores metadata and object databases to securely manage snapshots of your project.
- Seamless Collaboration: Git is fundamentally a distributed version control system, meaning every developer has a full, independent backup of the entire repository history.
- Branching Power: By understanding how Git commits branches, developers can create isolated environments to test features without breaking the main codebase.
Version control is essential for modern software teams. According to a recent survey by StackOverflow, Git is used by over 90% of developers, far surpassing other version control systems like SVN and Mercurial.
Have you ever wondered exactly how Git works and how it enables powerful features like branching, merging, and distributed collaboration?
In this article, we’ll unravel the inner workings of Git and illuminate the architecture that empowers its widespread adoption. We’ll explore concepts like distributed repositories, staging areas, commits, and more. You’ll learn how these components come together to enable game-changing workflows like feature branching and continuous integration.
Key Takeaways
- Git uses a three-stage architecture - working directory, staging area, and local repository to optimize change tracking.
- Key concepts like committing, branching, merging, and remotes enable powerful version control workflows.
- Git maintains an extensive history and provides commands like git log and git diff to analyze changes over time.
To experience Git first-hand, try the Git Branches Lab for free

Git Architecture & Components
While many version control systems use a two-tier architecture consisting of a repository and a working copy, Git distinguishes itself with a three-stage model optimized for tracking changes: the working directory, staging area, and local repository. Additionally, Git includes the concept of remote repositories for collaboration.
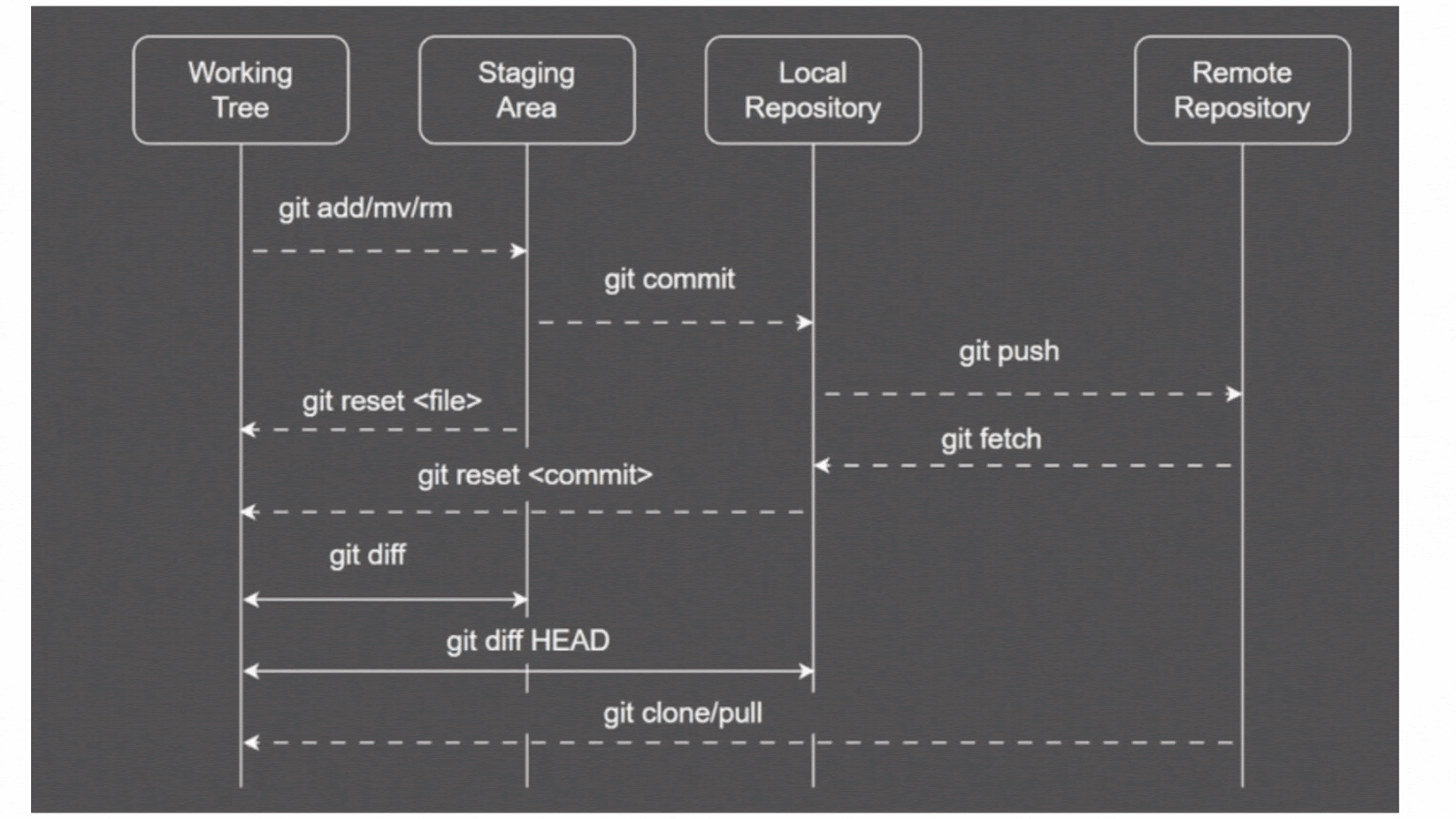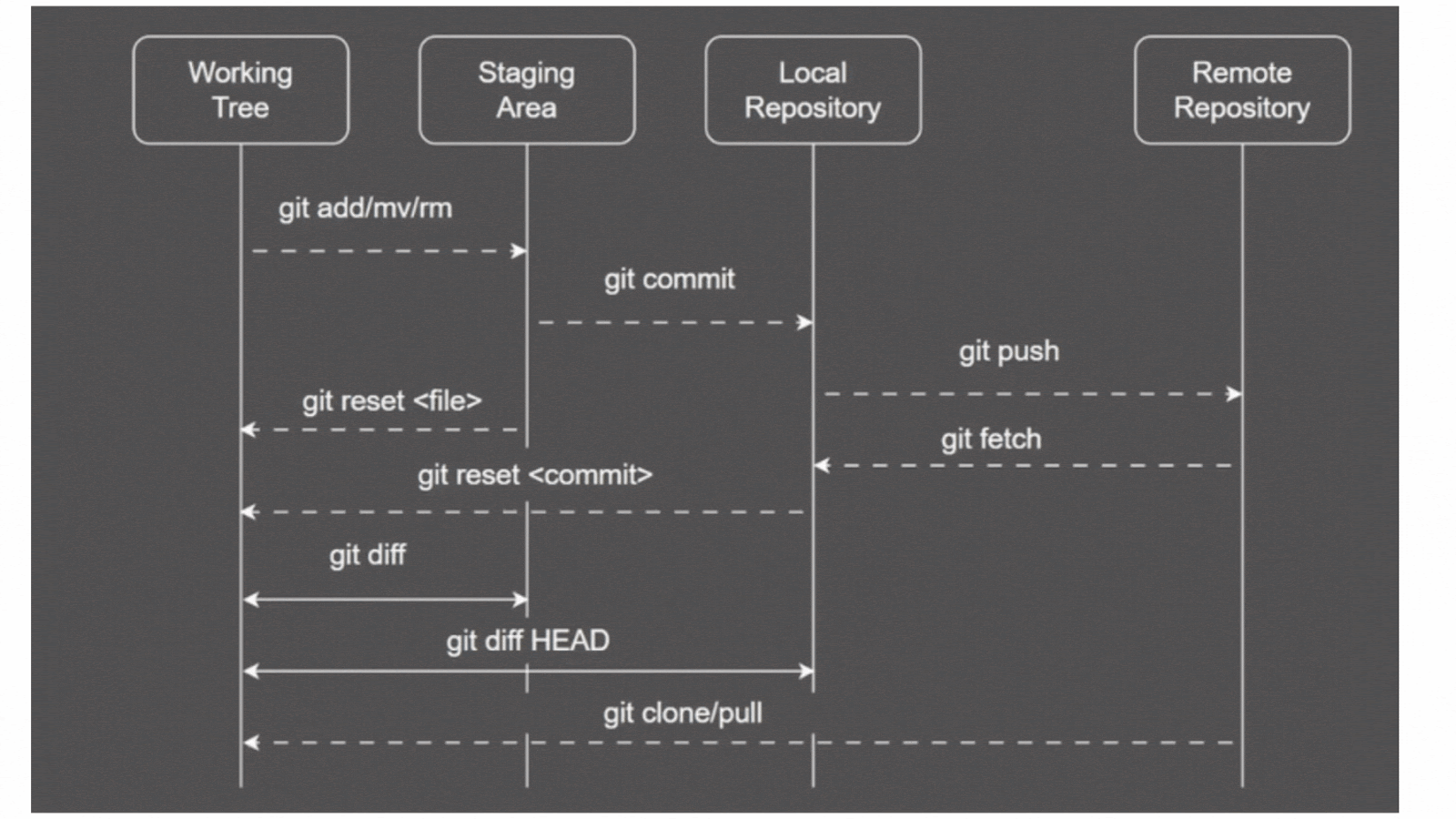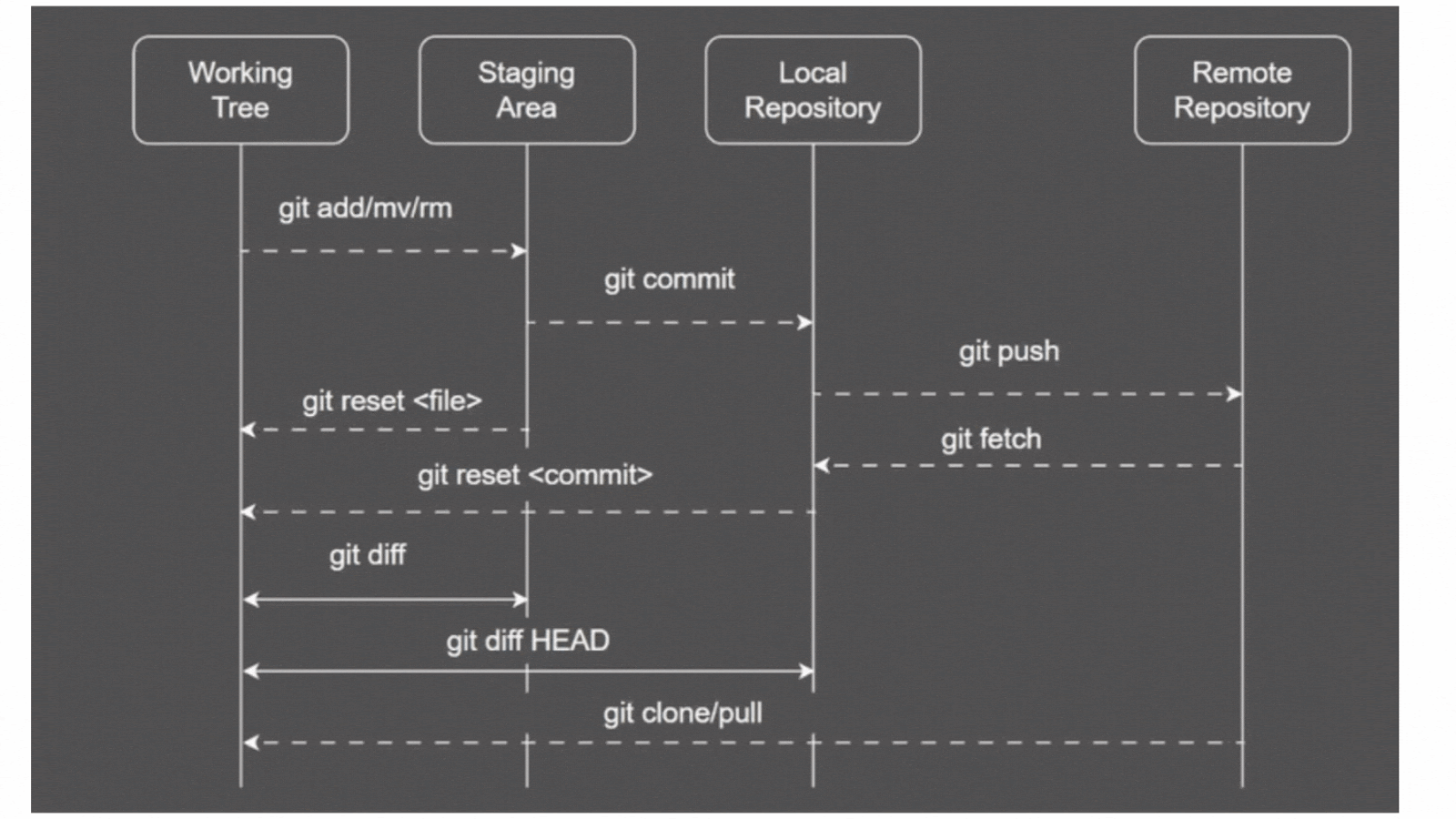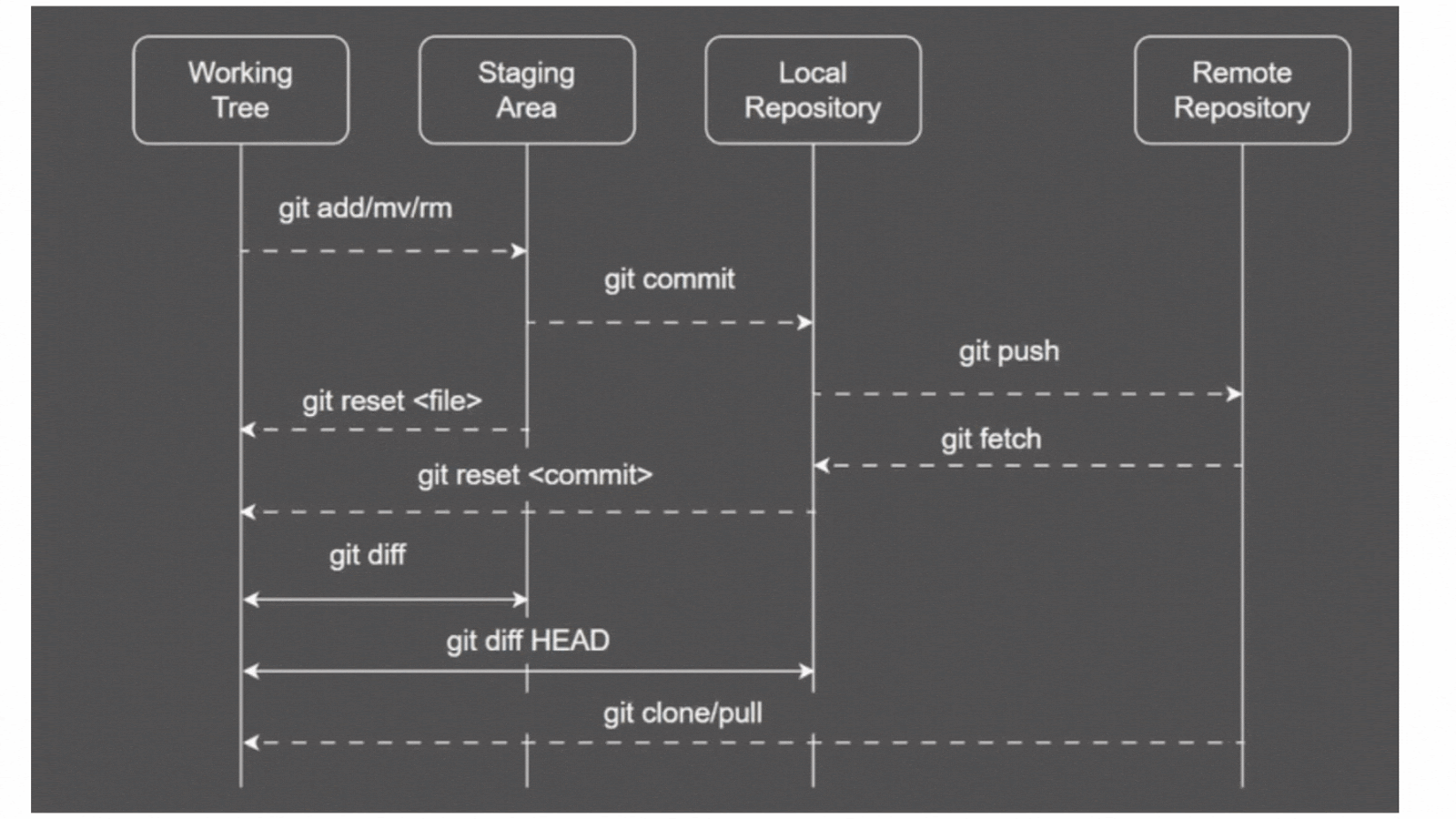
The three main components in Git each serve distinct roles:
- Working Directory: This is the actual directory where project files are located. Modifications made to files in the working directory are considered 'untracked' until explicitly staged for commit.
- Staging Area (Index): The staging area acts as an intermediate step between the working directory and the .git directory. Files in the staging area are 'staged' to be included in the next commit. This allows for a selective and controlled approach to committing changes.
- .git Directory (Local Repository): The .git directory serves as the core container for Git's version control system, containing metadata, object database, and configuration information. The .git directory stores committed snapshots, manages the project's history, and facilitates various Git operations.
As previously mentioned, in addition to these three components, Git leverages Remote repositories:
- Remote Repositories: Remote repositories serve as centralized hubs where team members can push and pull changes, ensuring a synchronized and collaborative development process.
Key Git Concepts
Git facilitates powerful version control and collaboration by employing a model based on commits, branches, merging, and remote repositories. This section explains how these key concepts work together to enable a seamless Git workflow.
Committing Changes
The commit lies at the heart of Git version control. A commit permanently stores changes from the working directory as a new revision in the project’s history. This creates a commit object with the following steps:
- Adding changes - The git add command stages edits from the working directory to be included in the next commit. This adds files to the staging area.
- Committing locally - The git commit command snapshots changes from the staging area and adds the commit to the local repository timeline creating a new revision. Commits always include metadata like a timestamp and author.
By repeating this edit, stage, and commit cycle, developers build up linear project history over time.
Branching
Branches act as movable pointers to different commits, allowing for parallel development. Understanding how Git commits branches and separates work environments is crucial. For example, we can create a new branch to add a feature without impacting the main codebase:
git branch new-feature
git switch new-featureNow you can make commits on the new-feature branch to develop the new feature while the main branch remains unchanged. This allows you to work on multiple streams of development in parallel.
- Creating branches - The git branch command generates new branch pointers, creating independent streams of development.
- Switching branches - Developers toggle between branches using the git switch command to work on features in isolation. Learn more about switching branches from this blog: Git Switch vs. Checkout: What’s the Difference?
Branching enables powerful workflows for testing ideas, fixing issues, and adding features without impacting the main code.
Merging
Merging integrates branch changes together, unifying divergent work into one codebase. Building on the previous example, once you complete a feature, you can easily merge it back into the main branch using the git merge command:
git checkout main
git merge new-featureTogether, branching and merging enable workflows for parallel development without impacting the main code.
Remotes
Remotes refer to shared repositories stored on remote servers. Teams collaborate across a network by:
- Pushing - Developers use git push to transfer commits from local repositories up to centrally hosted remote repositories like GitHub or GitLab.
- Pulling – git pull fetches the latest changes from remotes down to local machines so developers stay up to date.
This remote sharing model is what makes Git distributed, enabling incredible collaboration.
Common Commands in Git
While many commands exist for specialized Git workflows, developers primarily rely on a few commands for staging and committing changes:
- git init – Sets up the necessary configuration files and folders to initialize an existing directory as a fresh Git repository ready for version control.
- git clone – Creates a local duplicate of a repository. It copies the entire codebase, branches, and history and sets up remote tracking so the cloned repos stay in sync.
- git add – Marks files in the working directory that have been newly created or altered to be included in the next commit. This adds them to the staging area.
- git commit - Records the files within the staging area as a new commit in the repository update history.
- git push/pull – Synchronizes changes from a local repository to a remote repository. git push transfers committed changes to remote repositories, making them accessible to others collaborating on the same project. git pull retrieves the latest commits from the remote, updating the local repository with the changes made by others.
Git History & Version Tracking
Git maintains historical records and provides tools for understanding precisely when and how the code evolved.
Viewing History
The git log command is a powerful tool for examining the history of a Git repository. It displays a chronological list of commits, providing essential details such as authorship, dates, commit messages, and change statistics for the current branch.
Below are git log options you can use to narrow down the history to specific information.
- Commits introducing or modifying specific files
Use the following command to focus on commits related to a specific file or path:
git log -- filename or pathThis command helps you trace the history of changes to a particular file or directory.
- Commits by Specific Authors
To filter the log based on the commits made by specific authors, use:
git log --author="AuthorName"This command is useful when you want to examine the contributions made by a specific individual.
- Specific Date Ranges of Development
To filter commits made within specific date ranges of development, specify the time period you want to focus on. For example:
git log --since="2023-01-01" --until="2023-12-31"This command filters the git log output to only show commits made during the specified timeframe between the start date of 2023-01-01 and the end date of 2023-12-31.
- Changes to Code vs. Larger Architectural Changes
Utilize options like --grep and --oneline to distinguish between changes to code and larger architectural modifications.
- --grep="string" allows you to search for commits containing a specific string, helping you find changes related to a particular functionality or issue.
- --oneline condenses the log output, displaying each commit on a single line. This is useful for a more concise overview of the commit history.
Comparing Versions
The git diff command highlights differences between code versions, including commits, branches, and files in the working directory. It shows changes in history, diverging work in branches, and uncommitted changes. Additionally, it offers options for analyzing changes from various perspectives:
- Comparing the Staging Area to the Last Commit
To assess the disparities between the files in the staging area and the last commit, run this command:
git diff --staged- Analyzing Unstaged, Uncommitted Current File State:
For a detailed examination of the current state of unstaged and uncommitted files, run the command:
git diff- Compare Commits Across Branches
To compare commits between different branches, run the command:
git diff branch1..branch2This command will show the differences in content, additions, and deletions between branch1 and branch2.
Reverting Changes
If issues emerge, previous states can be restored using git reset, git checkout, or git revert:
- git reset rewinds history reverting undesired modifications
- git checkout directly extracts files from old commits
- git revert creates new commits undoing previous commits
With Git, you can see when changes to the code were made and can undo them. Undoing them returns the code to a state it once was in.
Customizing Git
Beyond tracking code changes, Git offers numerous ways to tailor and adapt its functionality to suit personal workflows or project needs. Customizations allow you to streamline repetitious commands, automate actions upon events, exclude temporary files from version control, and more.
Configuration Settings
Git configuration values are stored in .gitconfig files; we customize how Git works by adjusting the values in this file. The settings control:
- User information – Configures details like your name, email, and signing key for commit authorship.
- Useful settings – Customizes preferred text editor, pagination, line endings, and other interactions.
- Levels – Sets configuration precedence with local, global, and system-level settings. Local settings apply to a single repository. Global settings apply to all repositories for a user. System settings apply across the entire computer.
Aliases
Aliases defined in configs assign shortcuts for complex commands. For instance, an alias like git ci can be used instead of typing out git commit.
Aliases streamline workflows by chaining multiple actions into a single command. For instance, you could create an alias to checkout a branch, pull the latest changes, and open the project editor using the following command:
[alias]
workon = "!git checkout $1 && git pull origin $1 && code ."Now running git workon new-feature would switch to the new-feature branch, pull the latest remote changes, and open the project in VS Code - chaining all those steps into one alias command.
Hooks
Hooks in Git are triggers that execute custom scripts in response to specified events such as committing, merging, or pushing code. On the server side, hooks extend Git's functionality by managing actions such as backups, notifications, deployments, linting, and more, effectively enhancing Git's capabilities around these key events.
Ignoring Files
The .gitignore file outlines file patterns Git should intentionally exclude from version control, for instance, build artifacts, logs, dependencies, etc. Ignoring non-source files avoids polluting history with extraneous changes.
Learn how to effectively use and troubleshoot .gitignore from this blog: How to Fix "git ignore" Not Working Error?
Git Best Practices
Below are some best practices you should adhere to when using Git:
- Descriptive Commit Messages
Clear and well-crafted commit messages provide essential context regarding the reasons behind code changes. Good commit hygiene includes:
- Provide a brief and clear summary of commits using the subject line.
- Offer a thorough explanation in the commit body for intricate or complex changes.
- Use imperative statements in the present tense such as "Fix typo" or "Refactor code." Avoid passive statements like "Typo was fixed."
- Follow team conventions and frameworks like Conventional Commits to structure messages.
- Frequent Committing
Frequent committing results in a detailed history that captures small, incremental changes rather than sporadic heavy revisions. Some benefits include:
- Improved context on when and why updates occurred.
- Ability to revert tiny increments instead of big bang changes.
- Eases analyzing differences between versions.
- Encourages small single-purpose updates.
- Regular Synchronization
Smooth collaboration relies on consistently synchronizing local work with shared remote repositories. Make the following a habit:
- Pushing local commits often to share new changes with the team.
- Frequently pulling others' updates from remote repos to integrate cross-functional progress.
- Resolving integration conflicts immediately when they arise rather than allowing conflicts to accumulate. Early attention reduces troublesome merges.
- Strategic Branching
Leverage branches to compartmentalize defined types of development. Follow these best practices when working with branches:
- Keep canonical branches such as "main" and "develop" to consolidate ongoing progress.
- Create descriptive branches for features and fixes, isolating efforts (e.g., "payment-form").
- Implement version branches like "v1.0" for major milestones.
- Remove integrated branches to streamline active lines and enhance clarity in the project history. Learn more about deleting branches from this blog: How to Delete Local and Remote Branches in Git
- Leveraging .gitignore
Utilize the .gitignore file to exclude file patterns from version control (e.g., temporary files, compiled binaries, secrets). This will prevent the pollution of your commit history with extraneous changes unrelated to the core code.
Conclusion
At its core, Git simplifies version control through a commit-branch-merge-push cycle. This fundamental workflow, coupled with Git's distributed architecture, enables robust version tracking, scalable collaboration, and tailored workflows.
Interested in learning Git with simple visualizations and animations as well as by solving lab challenges, check out our Git for Beginners Course.
Q1: What is the easiest way to understand how Git works?
The best way to grasp how Git works is to understand its three-stage architecture: the working directory (where you edit files), the staging area (where you prepare changes), and the local repository (where snapshots are permanently saved).
Q2: What are the absolute Git basics every beginner should know?
The essential Git basics revolve around a handful of commands: git clone to copy a repository, git add to stage changes, git commit to save those changes locally, and git push/pull to sync with a remote server.
Q3: Why is Git called a distributed version control system?
Unlike centralized systems (like SVN) where the full history lives only on a single server, a distributed version control system like Git gives every single developer a complete, independent copy of the entire project history on their local machine.
Q4: How do Git commits branches help team collaboration?
Because Git commits branches act as lightweight, movable pointers, multiple developers can work on completely different features simultaneously without ever overwriting each other's code on the main branch.
Q5: How can I learn more about Git internals?
To understand Git internals, you can explore the hidden .git folder in your project directory. It contains the object database (blobs, trees, commits) and metadata that Git uses to cryptographically track every modification you make.














Discussion