



Highlights
- The “Back-Off Restarting Failed Container” error means your container keeps crashing and Kubernetes is delaying restarts.
- Most cases appear as CrashLoopBackOff in Kubernetes.
- Common causes include misconfigurations, missing dependencies, resource limits, and probe issues.
- Key diagnostic tools:
kubectl logs,kubectl describe, and checking Pod YAML. - Fixes often involve adjusting resource limits, correcting commands/env vars, or fixing liveness/readiness probes.
- Prevent issues with proper health probes, startup delays, and continuous monitoring of restart loops.
If you are a DevOps engineer working with Kubernetes, you might have encountered the 'back-off restarting failed container' error. This error indicates that your pod is stuck in a crash loop and cannot start properly. It can be frustrating and time-consuming to troubleshoot and fix this error, especially if you don't know the root cause.
In this article, we will explain what this error means, the common causes, and how to fix them. We will also share some tips and best practices to prevent this error.
What is 'back-off restarting failed container' Error?
The 'back-off restarting failed container' error is a Kubernetes state that indicates a restart loop is happening in a pod. It's a common error message that occurs when a Kubernetes container fails to start up properly and then repeatedly crashes.
Kubernetes has a default restart policy of Always, which means that it will try to restart the pod on failure. However, if the pod keeps failing, Kubernetes will apply a back-off delay between each restart attempt. The delay is exponential (10s, 20s, 40s, ...) and is capped at five minutes. During this process, Kubernetes displays the 'back-off restarting failed container' error.
Understanding Kubernetes Restart Behavior
Before diving into the causes, it helps to understand how Kubernetes handles container restarts and what “back-off” actually means.
The Default Restart Policy
By default, Kubernetes uses a restart policy of Always for most Pods managed by Deployments, ReplicaSets, and DaemonSets. This means that when a container inside a Pod crashes, Kubernetes will automatically try to restart it to maintain application availability.
However, Kubernetes also supports two other restart policies:
| Restart Policy | Description | Common Use Case |
|---|---|---|
| Always | The container restarts every time it exits, regardless of the reason. | Default for long-running workloads (Deployments, ReplicaSets). |
| OnFailure | The container restarts only if it exits with a non-zero code. | Used in batch Jobs or CronJobs. |
| Never | The container will not restart after termination. | Useful for debugging or short-lived tasks. |
In most real-world deployments, the Always policy ensures that Pods recover automatically from unexpected crashes.
What “Back-off” Means in Kubernetes
When a container keeps failing to start, Kubernetes doesn’t keep restarting it immediately. Instead, it applies a “back-off” mechanism, which increases the wait time before each restart attempt.
For example, the wait time typically grows exponentially:
10s → 20s → 40s → 80s → … (up to 5 minutes)
This mechanism prevents a container that continuously fails from consuming excessive cluster resources.
If you describe your Pod, you might see an event like this:
Warning BackOff 1m (x5 over 4m) kubelet Back-off restarting failed containerThis message simply indicates that Kubernetes is temporarily waiting before the next restart attempt. Once the back-off timer expires, it will try again.
You can check if your pod is in this state by running the command `kubectl get pods` and looking at the pod status. For example, you might see something like this:

This means that the pod my-app-6f8c9b7f4f-5xq2w has crashed five times and is waiting for the next restart attempt.
Common causes of 'back-off restarting failed container' error
There are many possible reasons why a pod might fail to start and enter a crash loop. Some of the common causes are:
- Resource overload or insufficient memory: Your pod might be crashing due to CPU or memory resource shortage. This can happen if you have memory leaks in your application, misconfigured resource requests, and limits, or simply because your application requires more resources than are available on the node.
- Errors when deploying Kubernetes: Your pod might crash from issues in the deployment configuration, such as incorrect image name, wrong environment variables, missing secrets, or invalid commands.
- Issues with third-party services: Your pod could crash if it depends on external services that have problems with DNS, database, or API. For example, your pod might fail to resolve a hostname, connect to a database, or authenticate with an API.
- Missing dependencies: Your pod needs certain dependencies in the image to run properly, such as libraries, frameworks, or packages. If these dependencies are missing, your pod might crash. For example, your pod might fail to load a module, execute a script, or run a command.
- Changes caused by recent updates: Your pod might be crashing due to changes in your application code, container image, or Kubernetes cluster that introduced bugs, incompatibilities, or breaking changes. For example, your pod might fail to parse a configuration file, handle an exception, or communicate with another pod.
How to fix 'back-off restarting failed container' Error
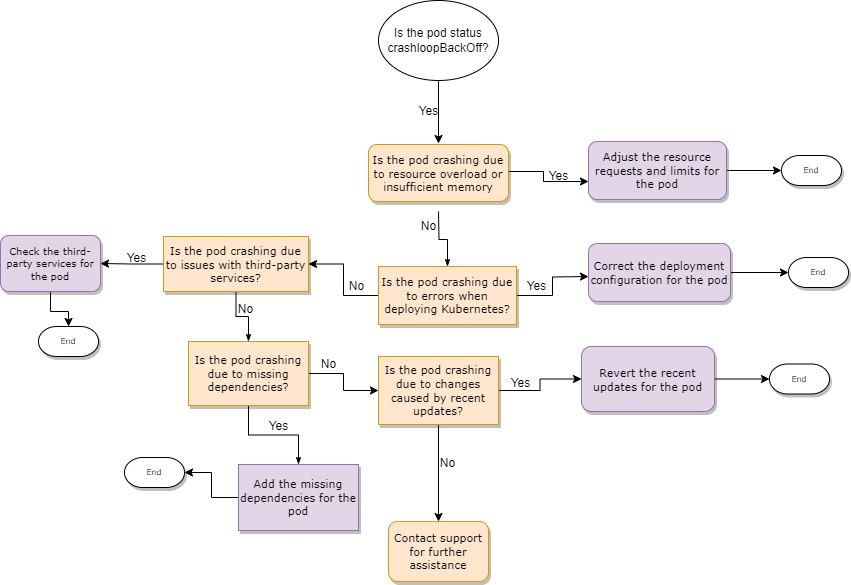
The first step to fix this error is to identify the root cause behind it. You can do this by inspecting the logs and events of the pod, as well as the status and description of the container. Here are some commands that can help you with this:
kubectl logs <pod-name>: This command displays the standard output and error of the container in the pod. To monitor the logs in real-time, use the `-f` flag or use the `--previous` flag to view logs from the previous instance of the container.kubectl describe pod <pod-name>: This command will show you detailed information about the pod, such as the pod spec, status, events, and conditions. You can look for any errors or warnings in the output, such asImagePullBackOff,ErrImagePull,ContainerCreating,CreateContainerError, orCrashLoopBackOff.kubectl get pod <pod-name> -o yaml: This command provides the YAML representation of the pod, which includes the pod spec and status. You can look for any errors or anomalies in the output like therestartCount,lastState,reason, ormessagefields.
Once you have identified the root cause, you can apply the appropriate fix for it. Depending on the cause, the fix might involve:
- Adjusting the resource requests and limits: Specify the minimum and maximum amount of CPU and memory that your pod needs using the `resources` field in the pod spec. This will help Kubernetes schedule your pod on a suitable node and prevent it from being evicted or killed due to resource starvation. For example:
# This is the original pod spec that causes the 'back-off restarting failed container' error due to insufficient memory
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-app
image: my-app:latest
command: ["python", "app.py"]
# This is the modified pod spec that fixes the error by specifying the resource requests and limits for the pod
apiVersion: v1
kind: Pod
metadata:
name: my-app
spec:
containers:
- name: my-app
image: my-app:latest
command: ["python", "app.py"]
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "500m"
memory: "512Mi"- Correcting the deployment configuration: You can use the
kubectl editorkubectl applycommands to modify your deployment configuration and fix any errors in it. Update the image name, environment variables, secrets, or commands that your pod uses. For example, you can use something like this:
image: my-app:latest
env:
- name: DB_HOST
valueFrom:
secretKeyRef:
name: db-secret
key: host
command: ["python", "app.py"]
- Checking the third-party services: Use
kubectl execto run commands inside your container and test the connectivity and functionality of the external services that your pod depends on. Also, use commands likeping,curl,telnet, ornslookupto check the DNS, network, or API services. For example:
kubectl exec -it <pod-name> – ping google.com
kubectl exec -it <pod-name> – curl http://my-api.com
kubectl exec -it <pod-name> -- telnet my-db.com 3306
kubectl exec -it <pod-name> – nslookup my-service.default.svc.cluster.local- Adding the missing dependencies: You can use the
kubectl execcommand to run commands inside your container to check the availability and version of the dependencies that your pod needs. Use commands likels,pip,npm, oraptto check the libraries, frameworks, or packages in your container. For example:
kubectl exec -it <pod-name> -- ls /usr/lib
kubectl exec -it <pod-name> -- pip list
kubectl exec -it <pod-name> -- npm list
kubectl exec -it <pod-name> – apt list --installedIf you find any missing or outdated dependencies, you can update your container image to include them and redeploy your pod.
- Reverting the recent updates: Use
kubectl rolloutto manage the updates of your deployment and rollback to a previous working version if needed. For example, you can usekubectl rollout historyto see the revision history of your deployment,kubectl rollout undoto undo the latest update, orkubectl rollout undo --to-revisionto undo to a specific revision. Below are examples of the commands you can use:
kubectl rollout history deployment/my-app
kubectl rollout undo deployment/my-app
kubectl rollout undo deployment/my-app --to-revision=2How to Prevent 'back-off restarting failed container' Error
The best way to deal with any error is to make sure it never happens at all. To do that, follow these best practices and tips when working with Kubernetes pods:
- Use
livenessProbeandreadinessProbefields in the pod spec to define health checks for your pod. These probes will tell Kubernetes when your pod is alive and ready to serve traffic and when it needs to be restarted or removed from the service. Here’s an example configuration:
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 15
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 15
periodSeconds: 10To learn more about probes, check out this blog: Kubernetes Readiness Probe: A Simple Guide with Examples
- Implement graceful shutdown using the
preStophook in the pod spec to define a command or a script that your pod should run before it is terminated. This will allow your pod to perform some cleanup or finalization tasks like closing connections, flushing buffers, or saving state. For example:
lifecycle:
preStop:
exec:
command: ["sh", "-c", "python shutdown.py"]- Properly monitor and collect logs and events from your pod using tools like kubectl and Kubernetes events. You can also use metrics and monitoring platforms like Prometheus, Grafana, or ELK to monitor pod performance and detect any issues. This will help troubleshoot and diagnose problems.
- Implement effective error handling in your code using try/catch blocks to gracefully handle exceptions or failures that occur. Also, use testing tools like Pytest, Mocha, or Jest to test your application logic and functionality. Testing and error handling will help you catch errors before an application is deployed.
- Manage your application code and container image versions using source control tools such as Git and packaging tools like Docker or Helm. Automate your deployment process with CI/CD pipelines using Jenkins, Travis CI, or GitHub Actions. Also, employ strategies like rolling updates, blue-green deployment, or canary releases when deploying to minimize downtime and reduce risk. Proper versioning and deployment processes help ensure stable, secure releases.
You can improve your Kubernetes skills with our courses right here at KodeKloud:
- Certified Kubernetes Administrator (CKA)
- Certified Kubernetes Application Developer (CKAD)
- Certified Kubernetes Security Specialist (CKS)
Conclusion
The 'back-off restarting failed container' error is a common and annoying error that can happen to any Kubernetes pod. However, by following the steps and tips in this article, you can easily identify, fix, and prevent this error from happening again.
Ready for hands-on learning? Subscribe now on our plan and pricing page to access 70+ top DevOps courses on Kodekloud. Start your journey today!
Let us know if you have any questions in the comments.
Also, you can explore more about this topic in this video:
FAQs
Q1: Does deleting the Pod reset the back-off timer?
Yes. When you delete a failing Pod, Kubernetes recreates it with a fresh back-off timer, which can help when you’ve already fixed the underlying issue but the Pod is still delayed from restarting.
Q2: How long does Kubernetes keep retrying before giving up?
Kubernetes never truly “gives up.” The restart delay increases to a max of ~5 minutes, but Kubernetes keeps retrying indefinitely as long as the Pod’s restartPolicy is Always.
Q3: Is CrashLoopBackOff always caused by my application code?
No. Many CrashLoopBackOff cases come from platform issues - like node pressure, DNS failures, missing Secrets, or overly strict probes - not from bugs in your code.
Q4: Can I see exactly when each restart happened?
Yes. You can track restart timestamps from Pod events and logs. Tools like Prometheus + Grafana, or stern/kubetail, make it easier to see restart patterns over time.













Discussion