



In part 1 of this 3-article series, we delved into how setting appropriate resource requests that closely reflect your workload resource utilization can help optimize your Kubernetes clusters. Now, you might assume that just like CPU requests, always setting CPU limits is the best practice in all scenarios. Well, “Life is not always black and white. It’s a million shades of grey”. Much like life, the effects of setting CPU limits or not for your varying workloads can be unpredictable, especially in a production environment filled with uncertainties.
There are quite a lot of controversies around setting CPU limits. Let’s get in and explore the impacts of setting CPU limits or not for workloads in your Kubernetes clusters.
Key Takeaways
- There are dangers both when you set CPU limits and when you don’t. Hence, continuous monitoring, alerting, and analyzing the behaviour of your production workloads is crucial to acting proactively and achieving defined SLOs.
- If you do set CPU limits, consider performing load testing, using Vertical Pod Autoscaler or open-source tools like Goldilocks to set appropriate values.
- If you don’t set CPU limits, consider placing workloads on dedicated nodes and CPU pinning.
The Dangers of Not Setting CPU Limits
Google recommends setting CPU limits as best practice. Even the Kubernetes Documentation highlights the following as the impact of not specifying the CPU limit:
- If the container without a CPU limit runs in a namespace with a set default CPU limit, it’ll automatically be assigned the namespace’s default limit.
- Not setting CPU limits could cause the containers to consume all the CPU resources available on the node where it is running. This can make critical Kubernetes processes, such as kubelet, to be unresponsive.
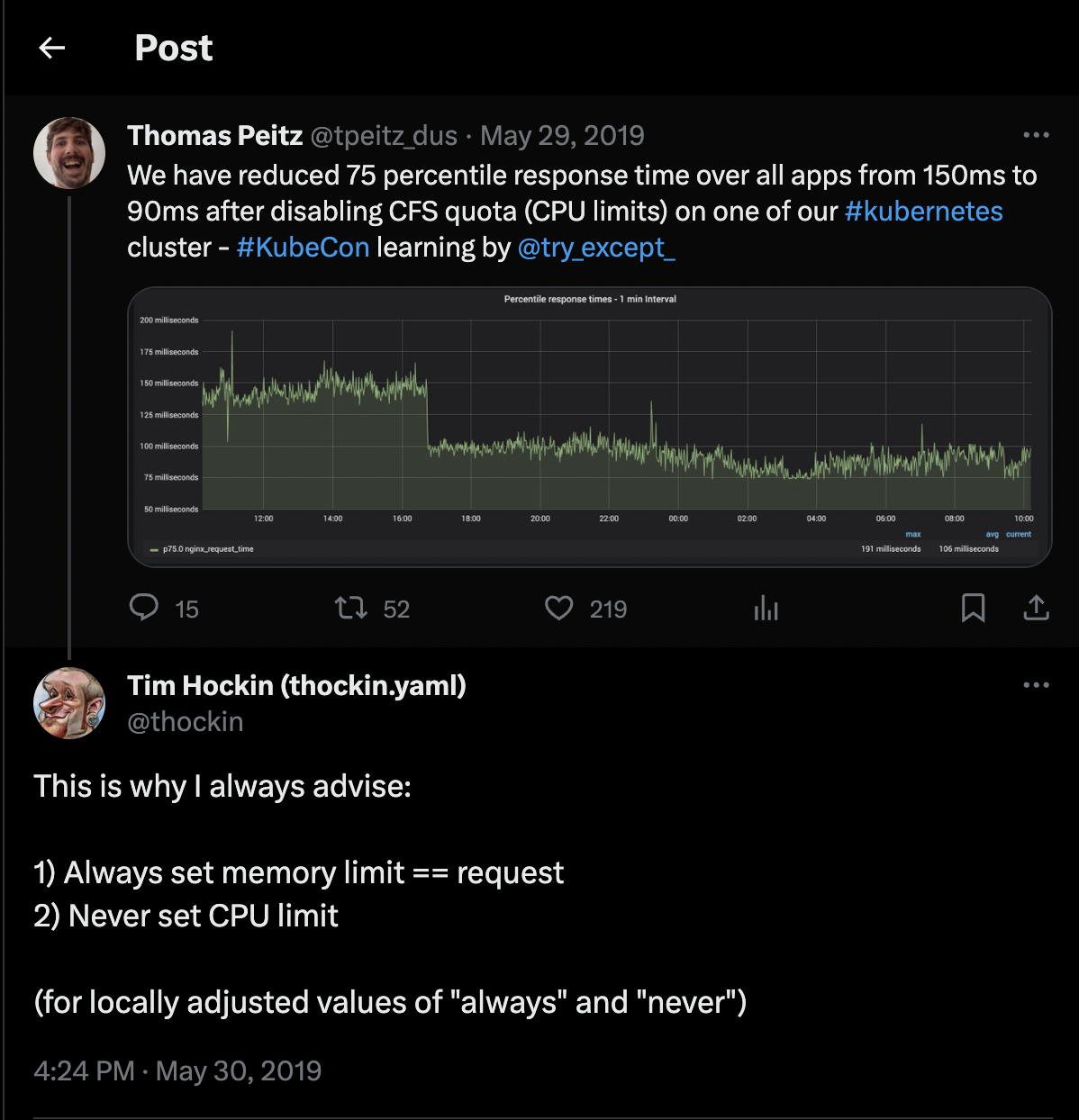
However, there are Kubernetes failure stories where setting CPU limits seems to cause more harm than good by impacting an application’s response time and increasing its latency. Let’s explore some of these failure stories next.
The Dangers of Setting CPU Limits
Kubernetes treats CPU and memory resources differently. Memory is non-compressible, while CPU is a compressible resource. This means that with memory if resource pressure occurs, the kubelet can only reclaim memory allocated to a container by killing that container. But with the CPU, it can be reclaimed by throttling (reducing CPU time available to a container). Sometimes, when CPU limits are set, throttling happens even with CPU usage that is way below the defined CPU limit. This causes poor application performance, especially for latency-sensitive applications.
These are some failure stories where setting CPU limits affected application response times:
- The Deep Learning Team at Numerator has Machine Learning (ML) models running as microservices on Kubernetes. They experienced increased throttling alerts and degraded performance after moving pods from a 4 vCPU node to a 16 vCPU node. They discovered that CPU requests guarantee a Pod gets the resources it needs and even bursts capacity to meet incoming load demands. So, setting CPU limits could lead to throttling and other performance issues, especially with multi-threaded workloads on high-core count nodes. Hence, based on their findings, they gave a recommendation to always set a memory limit to equal the memory request and never set a CPU limit.
- Buffer and Omio also experienced CPU throttling issues when CPU limits were set. Buffer discovered that even at a low CPU usage, CPU throttling could still happen. Buffer highlighted the cause could be a Linux kernel bug, which was later fixed. However, it seems it did not totally resolve the issue, as some throttling issues were still reported. They also had to remove CPU limits.
Tim Hockin, who is considered one of the key contributors to Kubernetes, also recommends never setting CPU limits and always setting memory limits to equal to memory requests.
You can get more insightful comments about this issue on this Hacker News thread.
Recommendations
Well, considering these different scenarios and suggestions regarding CPU limits, whether you end up setting CPU limits or not, continuous observability is crucial to analyze the behavior of your production applications and proactively make the necessary adjustments to deliver your defined SLOs. This will help you strike an optimal balance between cost and performance.
The goal should be finding that sweet spot based on your varying workload requirements and unpredictable real-world scenarios where the allocation of resources closely reflects the needs of your workloads to optimize cost without negatively impacting your end-user experience.
Additionally, if you want to set CPU limits to prevent CPU-intensive applications from consuming all available CPUs, consider using the Vertical Pod Autoscaler or open-source tools like Goldilocks to set appropriate CPU limits based on continuous observability. For your critical applications, consider performing load testing.
Also, if you don’t want to set CPU limits to avoid any level of throttling, consider placing those workloads on dedicated nodes. You can achieve this using Taints and Tolerations. This would help you easily detect and isolate any issues to just those nodes. This is what the team at Buffer did to deliver faster services.
In the same vein, you can consider adding CPU Pinning. This prevents Pods from jumping between different CPUs on the same node so that CPU-intensive workloads have exclusive CPUs.
You can also set up Readiness and Liveness probes to health-check containers in a Pod. Additionally, you can set up alerts regarding anomalies in the number of Pod restarts for specific workloads in your cluster.
Learn more about the Readiness probes and other probes from this blog: Kubernetes Readiness Probe: A Simple Guide with Examples.
Want to master container orchestration? Enrol in our Kubernetes Learning Path:

Wrapping up
What works in one scenario might not work for another, especially with varying Kubernetes workloads. We recommend you set up useful alerts and always continuously monitor the behavior of your workloads so that you can configure them appropriately.
In the final article of this 3-article series, we'll explore:
 Joy Adaeze Uchenna
Joy Adaeze Uchenna
More on Kubernetes:
- Security & Containerization
- Deploying, Maintaining, and Scaling Kubernetes Clusters
- Kubernetes Readiness Probe: A Simple Guide with Examples
- K3s vs K8s: What are the Differences & Use Cases
- How to Use Kubectl Scale on Deployment
- What is Argo CD? Concepts & Practical Examples
- Sidecar Container: What is it and How to use it (Examples)
- How to Use Kubectl Config Set-Context














Discussion