



Welcome to our exploration of the latest updates and changes in the newly released version of the Kubernetes platform – 1.30! This release, the first of 2024, includes 45 enhancements designed to improve functionality and performance. Let's dive into the highlights of this release.
If you'd prefer to watch a video instead of reading, check out our YouTube video on the latest Kubernetes 1.30 release here.
Introduction
Kubernetes 1.30 introduces a range of updates with 10 new or improved Alpha enhancements, 18 Beta enhancements now enabled by default, and 17 enhancements that have graduated to stable status.
The theme for the 1.30 release is “Uwubernetes.” This name combines "Kubernetes" with "UwU," an emoticon that represents happiness and cuteness, highlighting the community-driven nature of Kubernetes development.
Major Enhancements
1. Container Resource-Based Pod Autoscaling
Autoscaling is a crucial feature in Kubernetes, allowing the platform to automatically adjust the number of pod replicas based on resource usage or other metrics. The Horizontal Pod Autoscaler (HPA) typically scales pods based on overall resource usage, like CPU or memory.
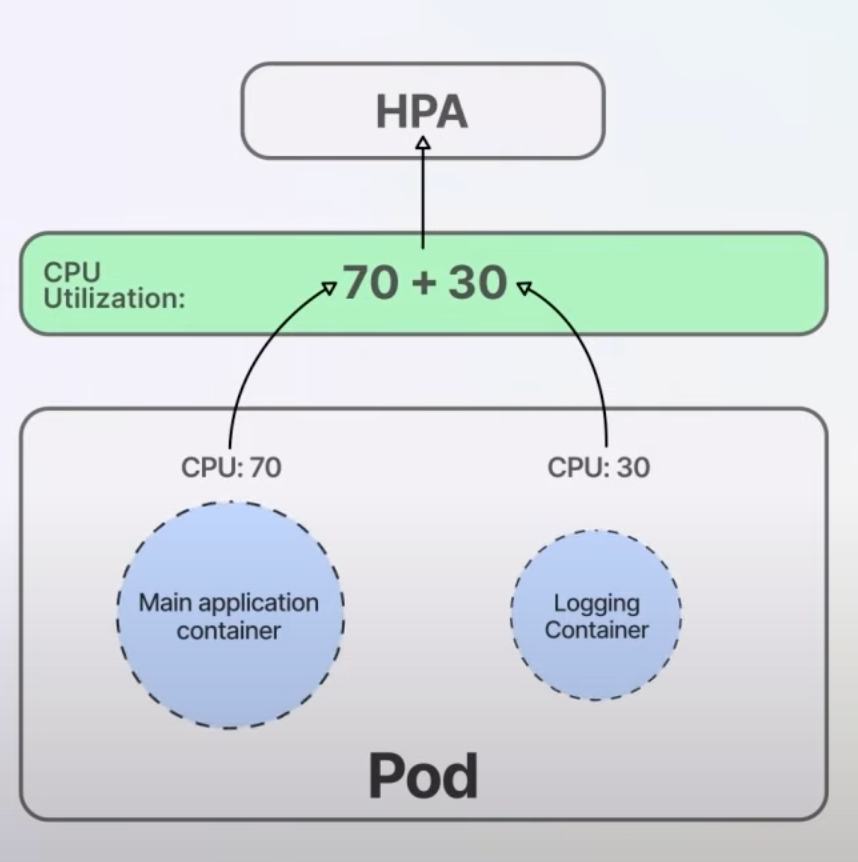
The Container Resource-based Pod Autoscaling feature focuses on the resource usage of individual containers within a pod, rather than combining the resources of all containers.
Previously, HPA would calculate resource utilization by summing up the usage of all containers in a pod. This could lead to inefficient scaling, especially if one container used significantly more resources than others. Now, with the ContainerResource type metric, HPA can monitor the resource usage of specific containers, ensuring more accurate and efficient scaling.
type: ContainerResource
containerResource:
name: cpu
container: app
target:
type: Utilization
averageUtilization: 70
Tip: If you're unfamiliar with Kubernetes Enhancement Proposals (KEPs), they are design documents that provide information about a new feature for Kubernetes.
2. Structured Parameters for Dynamic Resource Allocation (DRA)
Dynamic Resource Allocation (DRA) allows Kubernetes to manage resources like GPUs or storage more effectively. Prior to this update, the scheduling of these resources was less efficient due to limited visibility and communication delays.
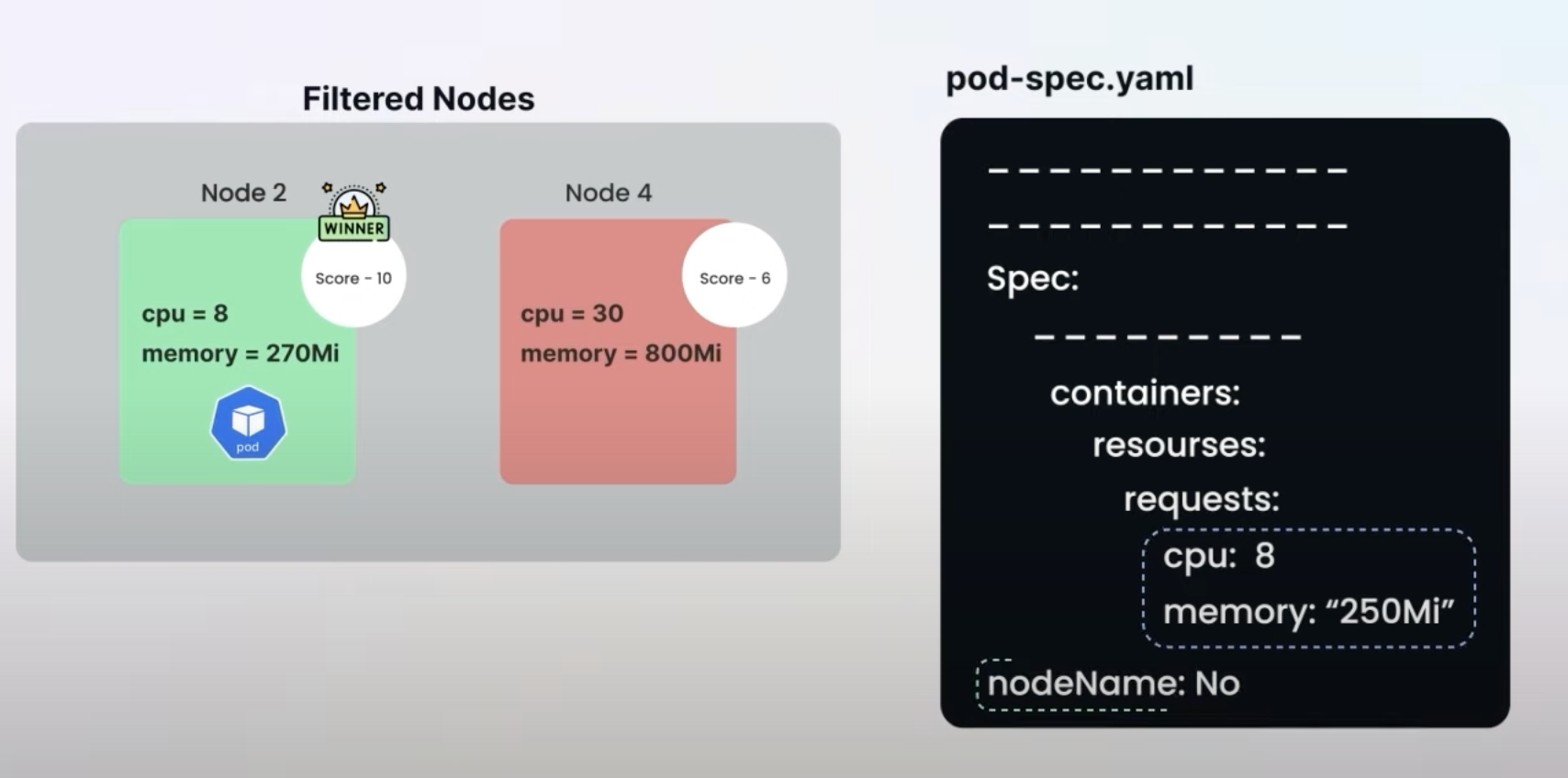
The introduction of structured parameters for DRA allows the Kubernetes scheduler to have direct access to a detailed list of available resources, improving scheduling efficiency.
Before this enhancement, third-party drivers marked ResourceClaims as "allocated," but the scheduler lacked direct insight into available resources. This caused delays and inefficiencies. Now, with ResourceSlice objects, the scheduler can directly allocate resources, reducing the need for extensive back-and-forth communication with resource drivers.
apiVersion: dra.k8s.io/v1beta1
kind: ResourceClaim
metadata:
name: advanced-resource-claim
spec:
resourceType: "gpu"
resourceParameters:
attributes:
model: "nvidia-tesla-v100"
capacity: "16GB"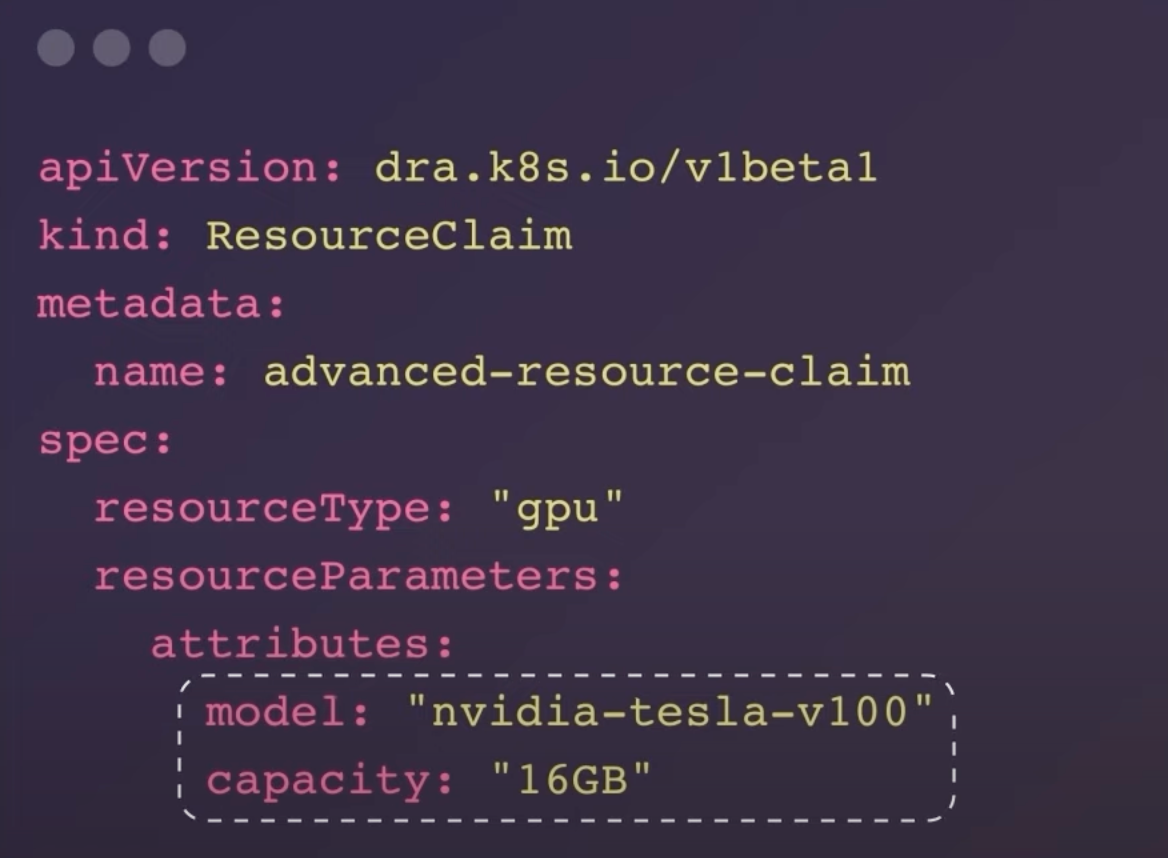
Tip: Dynamic Resource Allocation helps in scenarios where you have advanced resource needs, such as using GPUs for machine learning tasks.
3. Node Memory Swap Support
Swap memory acts as an overflow for your computer's RAM, using disk space to store data when RAM is full.
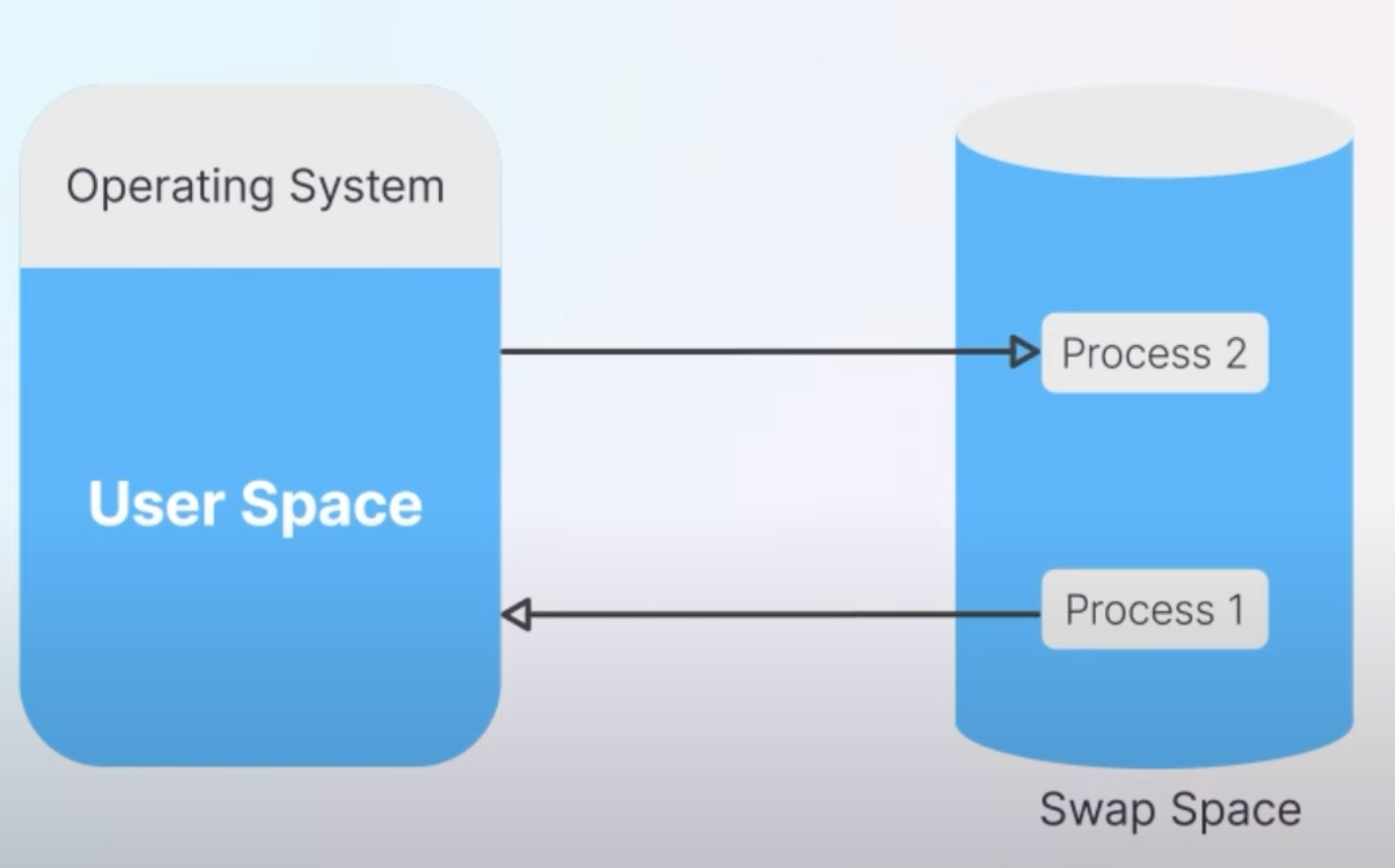
However, Kubernetes had swap memory disabled by default, which could lead to stability issues when node memory was exhausted.
Kubernetes 1.30 introduces better management of swap memory, offering modes like NoSwap and LimitedSwap to enhance system stability.
In NoSwap mode, pods do not use swap space, ensuring other system processes that require swap can still function. LimitedSwap mode allows pods to use a controlled amount of swap space, preventing excessive swapping and maintaining better performance.
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
failSwapOn: false
featureGates:
NodeSwap: true
memorySwap:
swapBehavior: LimitedSwapTip: Swap space can be beneficial in environments where you want to ensure system stability without crashing due to memory exhaustion.
4. Structured Authorization Configuration
Authorization in Kubernetes controls who can do what within a cluster. Managing these settings has traditionally been complex.
The structured authorization configuration, now in Beta, simplifies managing authorization settings through a configuration file and supports dynamic reloading and detailed metrics reporting.
With dynamic reloading, the API server automatically updates its configuration when the authorization file changes, without needing a restart. Metrics provide insights into authorization decisions, helping administrators understand the effectiveness of their policies.
5. UserNamespace Support in Pods
User namespaces in Kubernetes enhance security by isolating the User IDs (UIDs) and Group IDs (GIDs) of processes running in pods from those on the host system.
Kubernetes 1.30 improves user namespace support, allowing administrators to specify exact ID ranges for UIDs and GIDs, preventing overlap with host IDs.
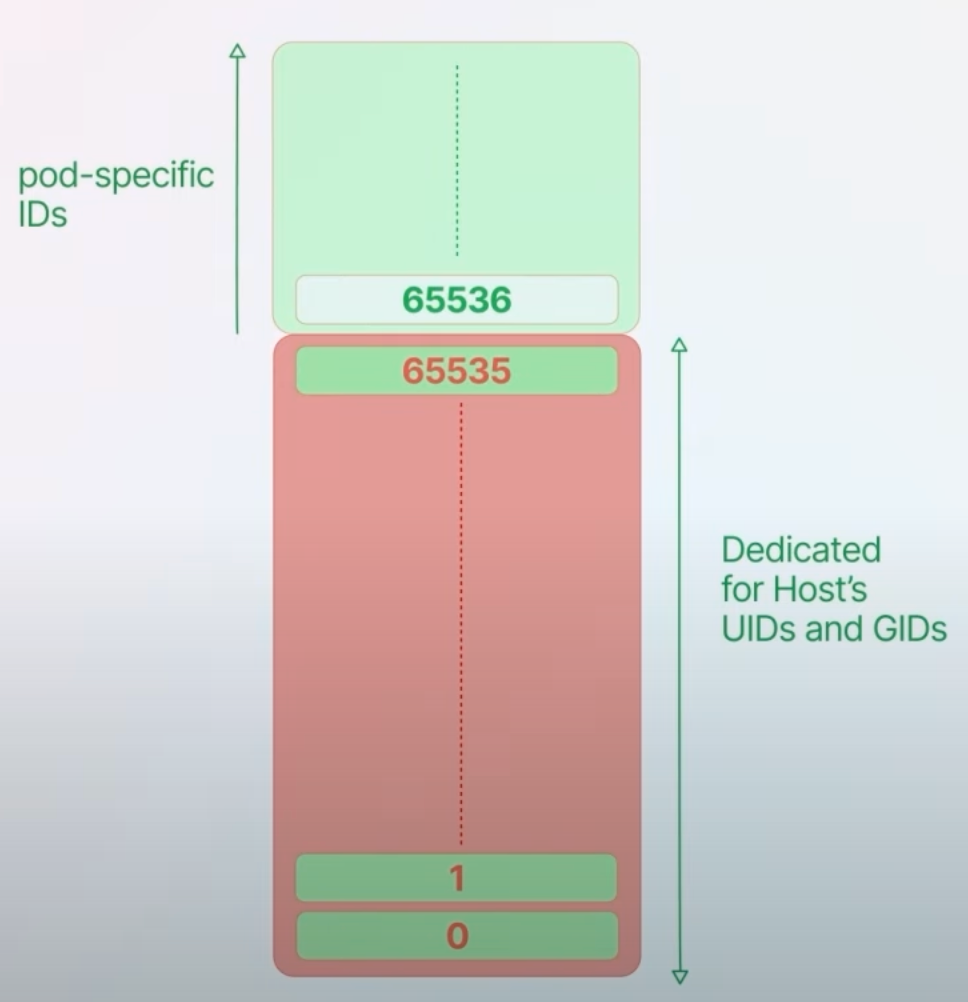
This enhancement helps avoid security risks like unauthorized file access by ensuring pod-specific IDs do not conflict with host IDs. It provides better security isolation between container runtime environments and the host system.
apiVersion: v1
kind: Pod
metadata:
name: usernamespace-demo
spec:
securityContext:
runAsUser: 100000
runAsGroup: 100000
containers:
- name: example
image: example/image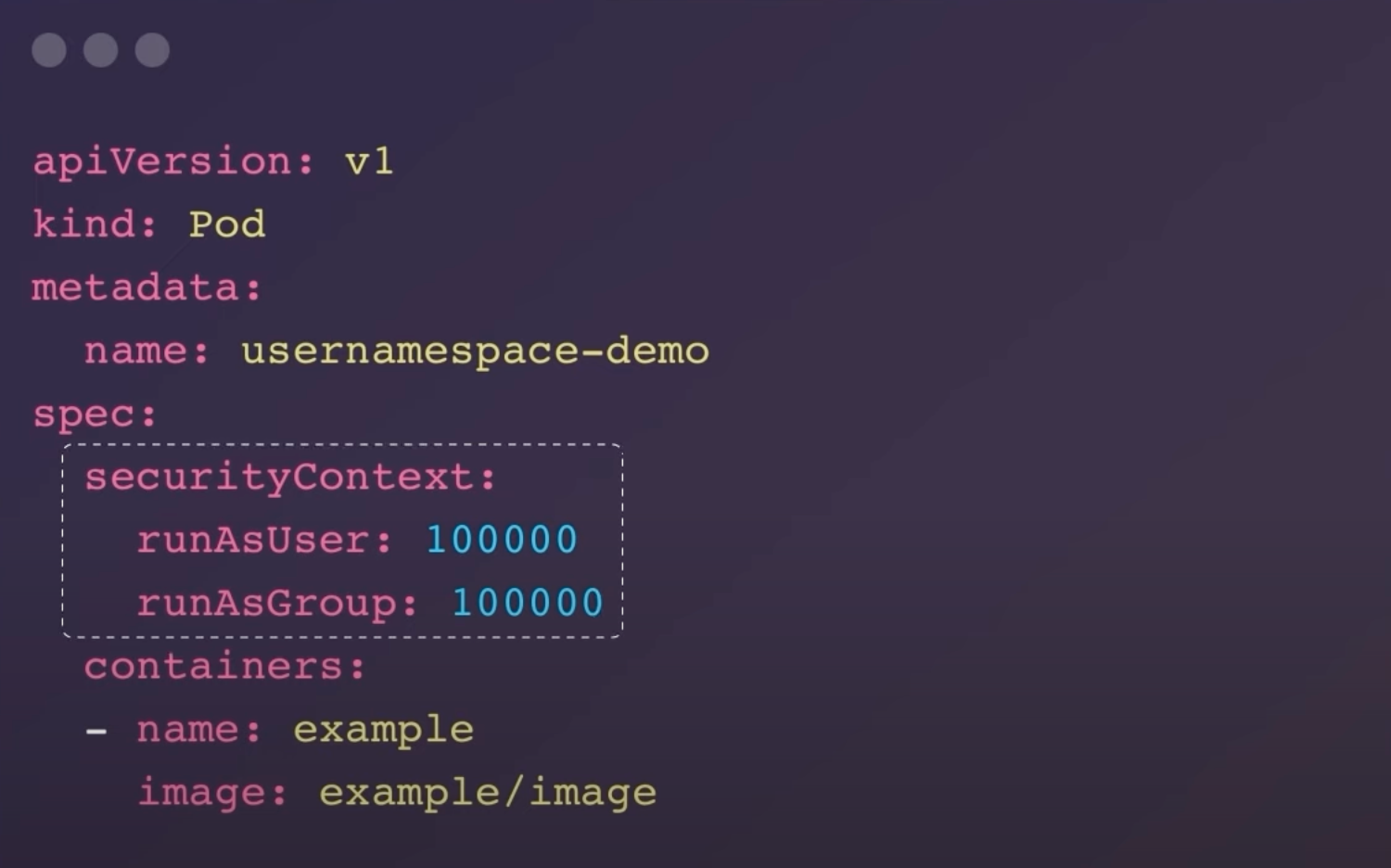
Tip: Configuring UID/GID ranges correctly is crucial for maintaining security and avoiding conflicts with host IDs.
6. SELinux Label Optimization
SELinux (Security-Enhanced Linux) is a security architecture that enforces security policies on processes and system resources. In Kubernetes, SELinux ensures pods comply with host security policies.
Kubernetes 1.30 introduces optimizations for applying SELinux labels, making the process faster and more efficient.
Previously, applying SELinux labels to volume contents was slow and resource-intensive. The new optimization uses a mount option that applies labels in constant time, regardless of the number of files and directories, significantly improving performance.
apiVersion: v1
kind: Pod
metadata:
name: secure-pod
spec:
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
containers:
- name: nginx
image: nginx
securityContext:
seLinuxOptions:
level: "s0:c123,c456"
volumeMounts:
- mountPath: "/data"
name: secure-volume
volumes:
- name: secure-volume
persistentVolumeClaim:
claimName: secure-pvc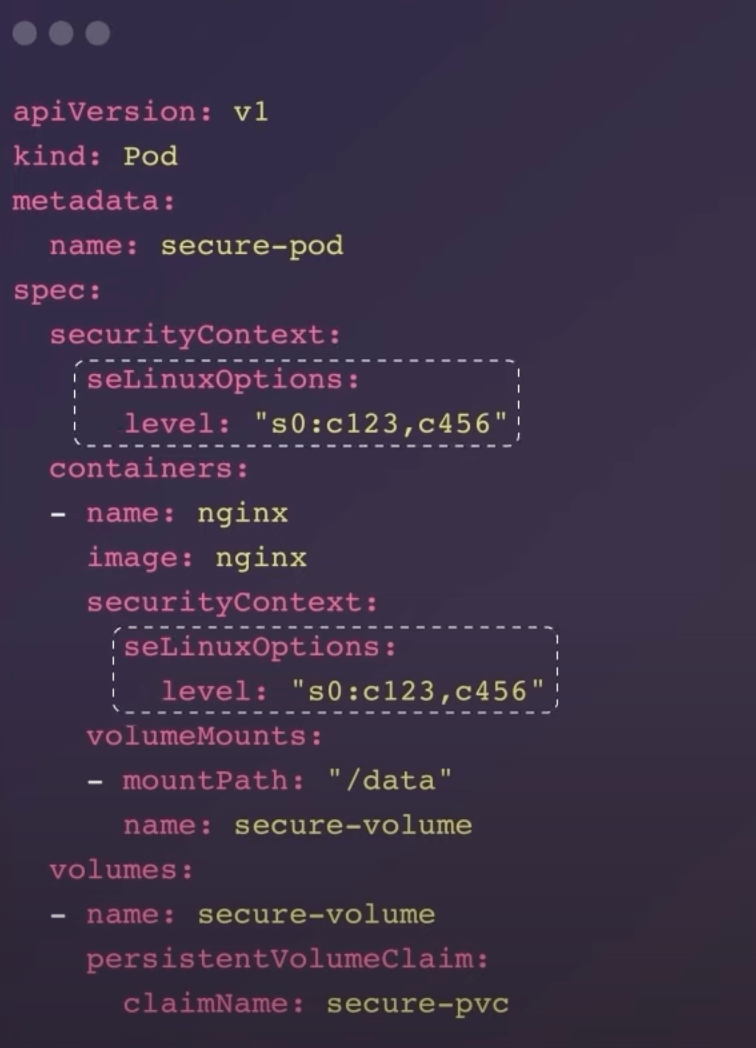
Tip: Using SELinux labels helps maintain strict security policies, especially for sensitive data volumes.
7. Job Success/Completion Policy
In Kubernetes, Jobs are used to run batch processes. Traditionally, all pods in a job needed to succeed for the job to be considered complete.
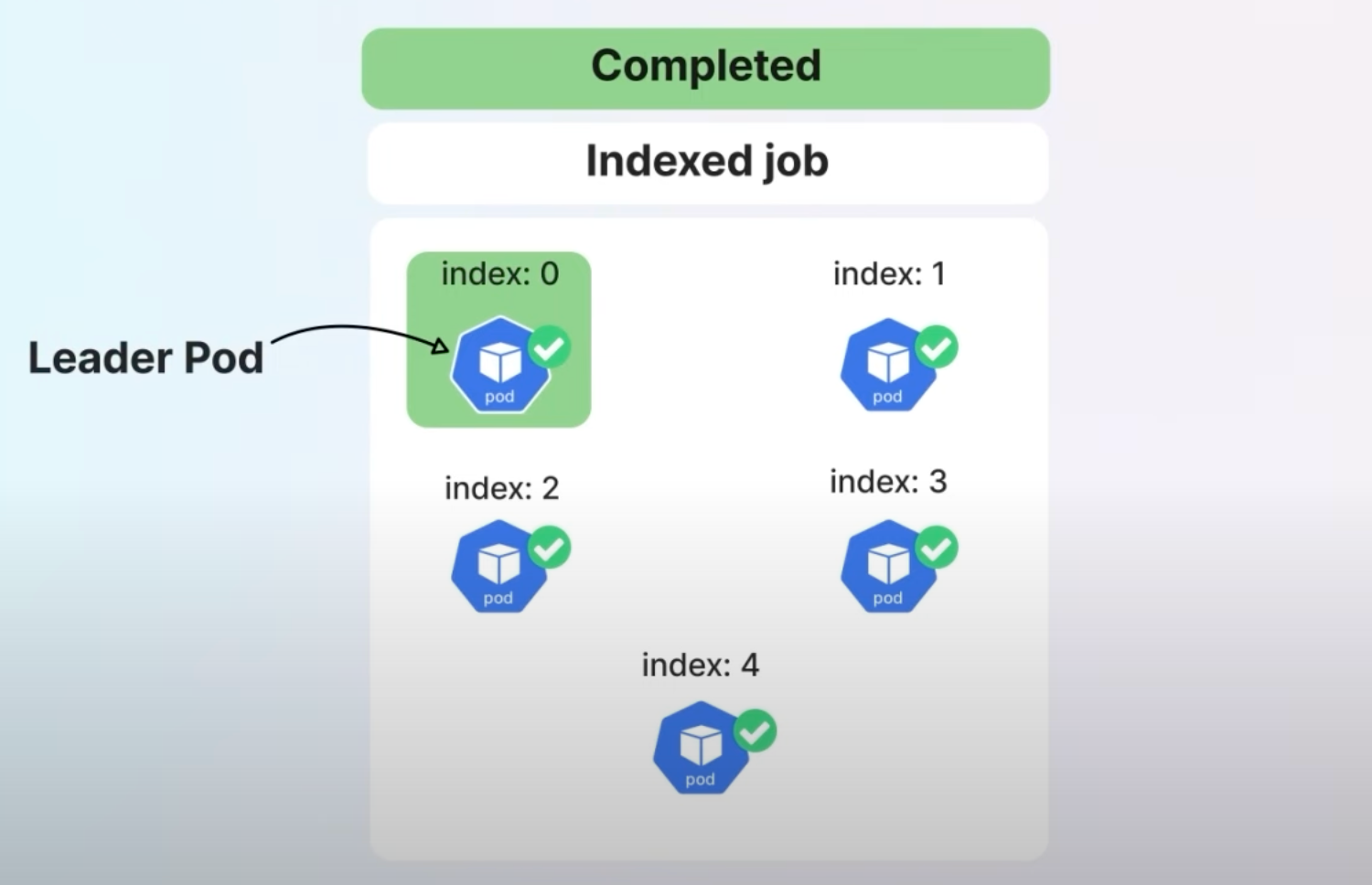
The Job Success/Completion Policy allows defining custom success criteria for Jobs, particularly Indexed Jobs, which is useful in complex fields like machine learning and scientific research.
This feature lets users specify conditions under which a job should be considered successful, such as the success of specific pods or a count of successful pods. This allows for more efficient resource usage and job management.
apiVersion: batch/v1
kind: Job
spec:
parallelism: 10
completions: 10
completionMode: Indexed
successPolicy:
criteria:
- succeededIndexes: "0"
template:
spec:
restartPolicy: Never
containers:
- name: job-container
image: job-image
command: ["./sample"]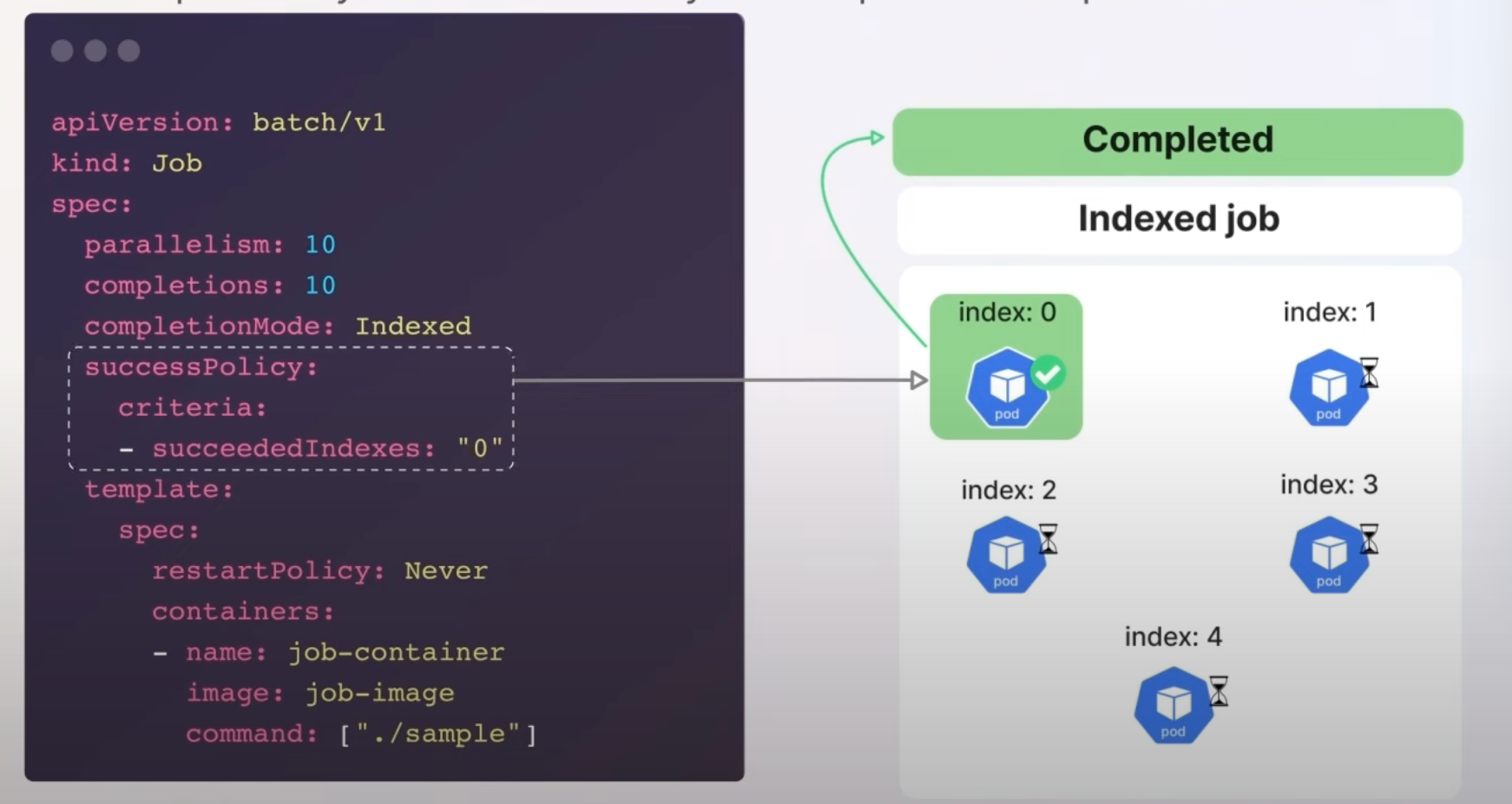
Tip: This policy is especially beneficial for distributed applications where only certain tasks need to succeed for the overall job to be successful.
8. Interactive Mode for kubectl delete
The kubectl delete command can remove critical resources, and a simple typo could lead to significant data loss or operational disruptions.
The interactive mode for kubectl delete, now stable, adds a confirmation step to prevent accidental deletions.
Using the --interactive or -i flag, kubectl delete provides a preview of resources to be deleted and prompts the user for confirmation, enhancing safety.
$ kubectl delete -i -f test_deployment.yaml
You are about to delete the following 2 resource(s):
Deployment/dockerd
Deployment/dockerd2
Do you want to continue? (y/n): y
deployment.apps "dockerd" deleted
deployment.apps "dockerd2" deleted
Tip: Always use the interactive mode when deleting multiple resources to avoid accidental deletions.
9. Routing Preferences for Services
Background: In Kubernetes, services route traffic to pods, but previously there wasn't a straightforward way to control how traffic is distributed among service endpoints in different zones. This often led to inefficient routing and higher cross-zone networking costs.
The new spec.trafficDistribution field allows users to specify routing preferences, such as preferClose, which prioritizes sending traffic to endpoints within the same zone as the client.
With the preferClose setting, Kubernetes aims to minimize latency and reduce networking costs by routing traffic to the nearest available endpoint. If no endpoints are available in the client's zone, traffic is routed to other zones.
Let's say you have an online retail application deployed across multiple zones (Zone A, Zone B, and Zone C). Before this update, when a user in Zone A accessed the application, the request could be routed to an endpoint (pod) in Zone C or any other zone, leading to higher latency.
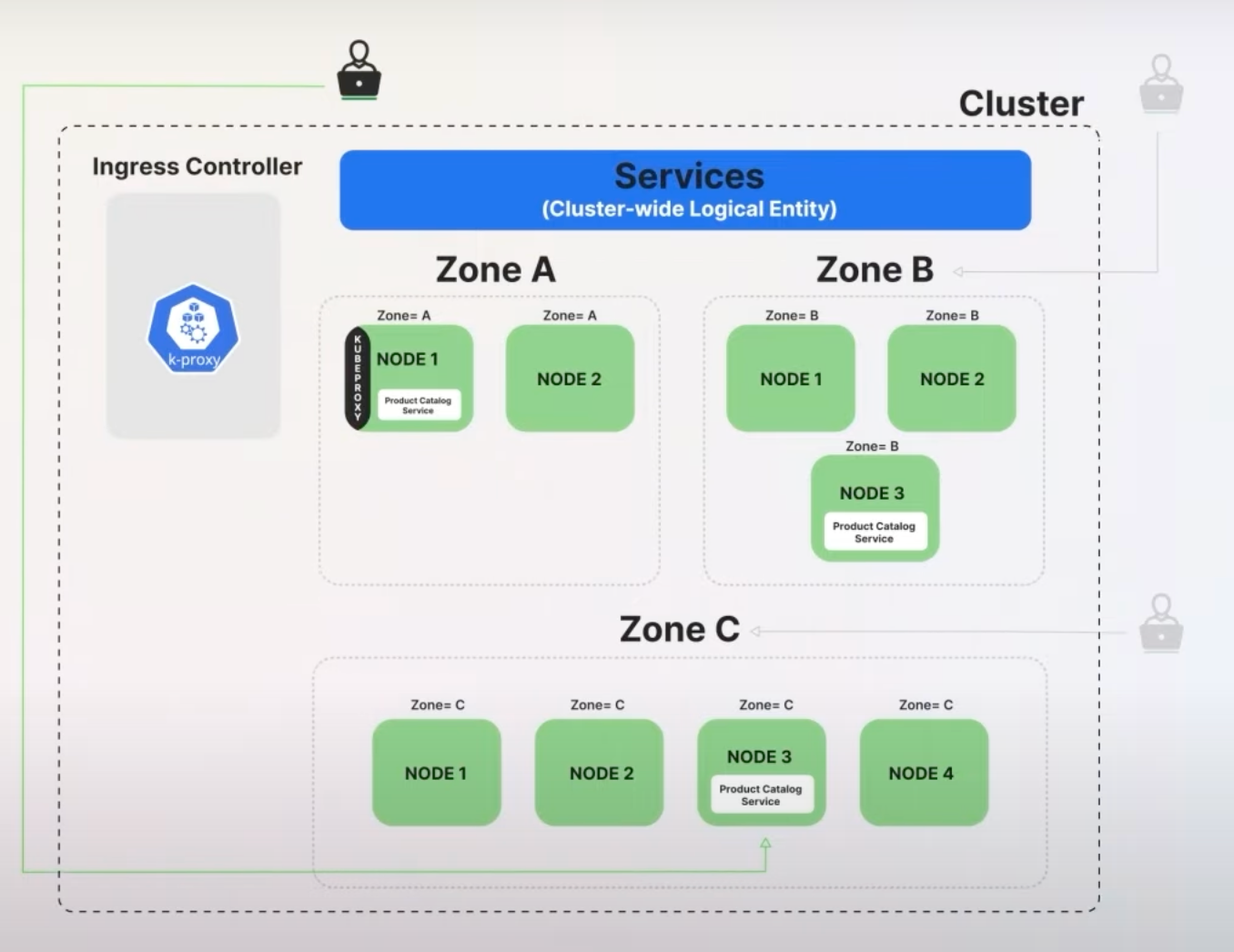
With the preferClose setting, the request is now routed to an endpoint in Zone A if one is available.
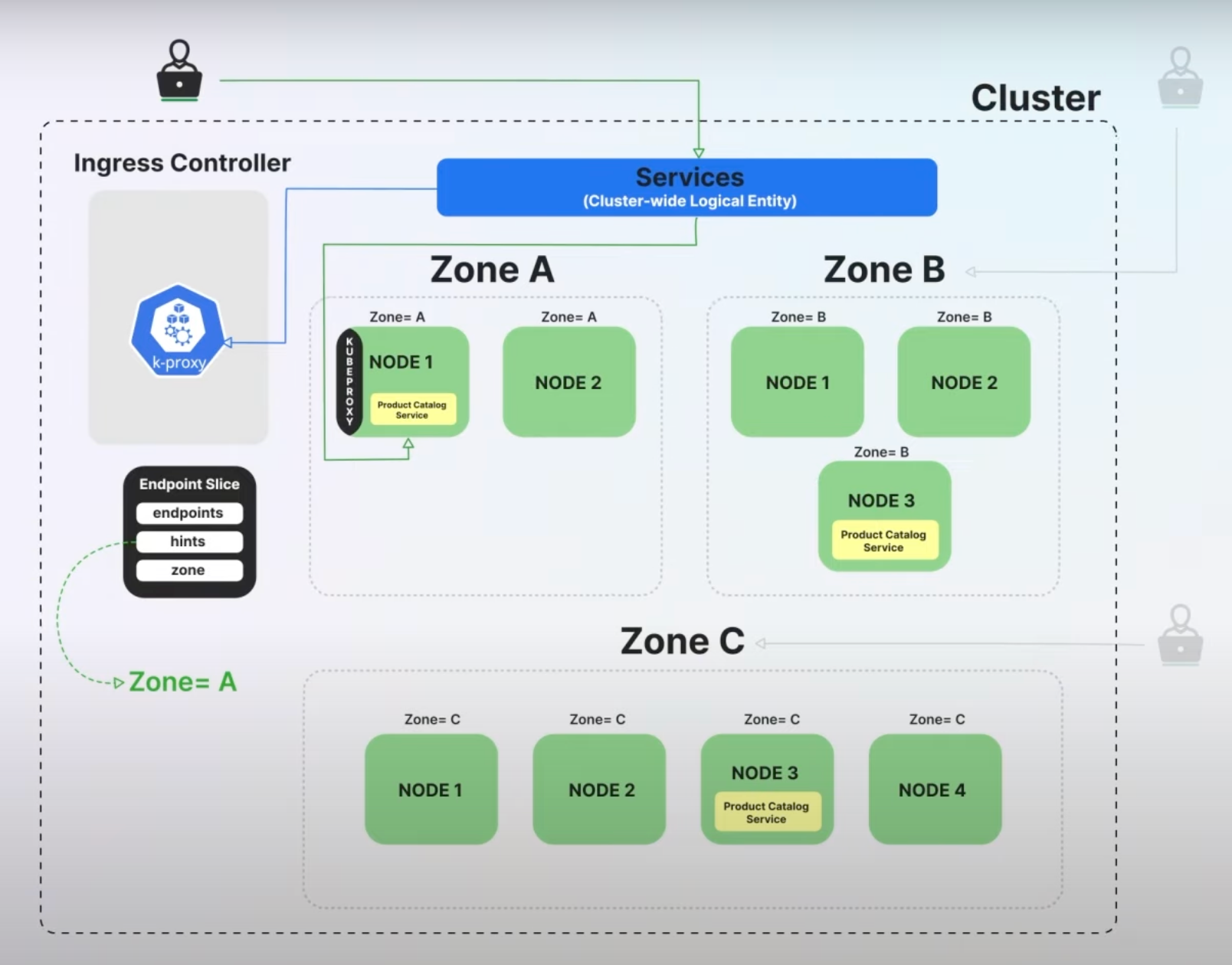
This reduces latency because the traffic doesn't need to travel between zones. If all pods in Zone A are unavailable, the traffic will be routed to Zone B or Zone C, ensuring the service remains available.
apiVersion: v1
kind: Service
metadata:
name: my-service
spec:
selector:
app: MyApp
ports:
- protocol: TCP
port: 80
targetPort: 9376
trafficDistribution:
preferClose: trueTip: Ensure your nodes are correctly labeled with their respective zones to make the most of this feature. For clusters not hosted on cloud infrastructure, administrators need to manually label nodes with topology information.
Additional Highlights
Several features have graduated to stable, including the reduction of secret-based service account tokens, CEL for Admission Control, and the Node Log Query. These features enhance security and functionality, building on improvements from previous releases.
For a deeper dive into all the new features and updates, you can visit the official Kubernetes release notes.
That’s all for now! Stay tuned for more updates and happy Kubernetes-ing!











Discussion