



Highlights
- File manipulation is essential in DevOps, scripting, and automation, especially when working with logs, data files, or configuration files.
- You created a sample
names.txtfile using a heredoc (<< EOF) and verified it usingcatandrealpath. - You learned two ways of reading files line by line in Bash:
- Using a while loop - memory-efficient, safest for large files, and ideal for production scripts.
- Using a for loop - works for small files but loads the entire file into memory, which can cause issues with long or complex files.
- You saw how environment variables like IFS (Internal Field Separator) influence how for-loops process lines.
- You explored how to create and run scripts inside /usr/local/bin, using your system’s PATH to execute them easily.
- The blog included beginner-friendly explanations of shebangs, command substitution, read -r, and input redirection (
< filename). - Final takeaway:
Use a while loop for reliability and performance; use a for loop for quick and small tasks.
File manipulation is an essential skill when dealing with scripting and automation. Whether you’re analyzing log files, processing data sets, or parsing configuration files, the ability to read and interpret file content is critical.
In Bash scripting, one of the most common tasks is to read a file line by line in Bash, whether you're parsing logs, configuration files, or automation outputs.
In this blog post, we’ll learn how to read a file line by line in Bash using while and for loops. Let’s get started!
What You Need to Get Started
To try out the scripts in this blog post, you need access to a Bash shell. You also need a text editor, such as "nano" or "vim", which come pre-installed by default in many Unix-like operating systems.
For the purpose of this blog post, I'll be using KodeKloud’s Ubuntu playground, which lets you access a pre-installed Ubuntu operating system in just one click. Best of all, you won't need to go through the hassle of installing any additional software- everything you need is already set up and ready to use.
This makes it perfect for practicing different methods of reading files in Bash scripts, including while-read loops, for-loops, and IFS-based parsing.
How to Create a Sample File
In this blog post, we'll be working with a sample file called names.txt, which will contain five names. Here's how to create that file and fill it with the necessary data:
Open a terminal window and navigate to the directory where you want to create the file. Then, run the following command:
cat << EOF >> names.txt
Jane Smith
John Doe
Alice Johnson
Bob Brown
Charlie Davis
EOFIn this command:
<< EOF: Starts aheredocument (also referred to as a "heredoc"). It's a way to pass multiline input to a command. Theheredocument starts with<<followed by a delimiter. In our example,EOF(End Of File) is used as the delimiter, but it's really just a convention; you could use any word or phrase as long as it's the same at the beginning and the end of theheredocument.>> names.txt: Tells the shell to append the contents of theheredocument tonames.txt.- The lines between
<< EOFand the secondEOFare the contents of theheredocument. These lines will be appended tonames.txt.
Later in this post, we’ll use this file to demonstrate how to parse text file in Bash using simple and advanced looping structures.
To confirm that the file has been created, and the names have been written to it, run the following command to display its contents:
cat names.txtYou should see the file content printed on your terminal like this:
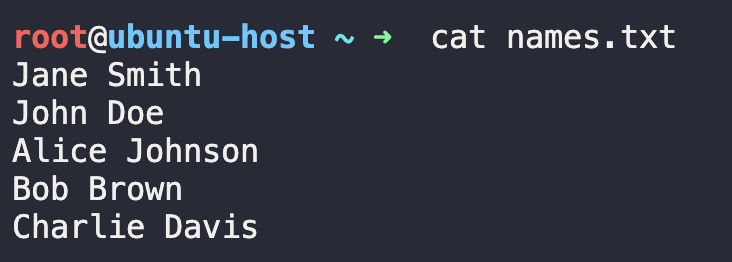
We now have a file called names.txt, filled with five names, that will be used in the examples throughout the post.
Once the file is created, we’ll later explore how to parse a text file in Bash using efficient and safe techniques.
Next, let’s get the full path of the file (we’ll need this for a later section) by running the following command:
realpath names.txtYou should see the full path displayed on your terminal, as shown below:

Reading a File Line By Line in Bash With a While Loop
A while loop is a commonly used method for reading a file line by line. In this section, we'll write a Bash script that leverages a while loop to read the contents of our names.txt file, one line at a time.
First, let’s create a script file named demo.sh in the /usr/local/bin directory and open it using the nano editor.
Note: While you're free to create the demo.sh file in any directory of your choice, we're placing it in the /usr/local/bin directory for a specific reason. In most Linux distributions, this directory is included in the system's command path. This means we can run our script without making it executable.
To confirm whether the /usr/local/bin directory is part of your command search path, run the following command:
$PATH
As you can see, the /usr/local/bin directory is indeed included in the PATH, which is essentially a list of directories that your system searches when attempting to execute a command.
Now, to create and open the demo.sh file in the nano editor, run the following command:
nano /usr/local/bin/demo.shThis will launch the nano editor as shown below:
Now, add the following script to the editor:
#!/bin/bash
# Define the input file
INFILE=/root/names.txt
# Read the input file line by line
while read -r LINE
do
printf '%s\n' "$LINE"
done < "$INFILE"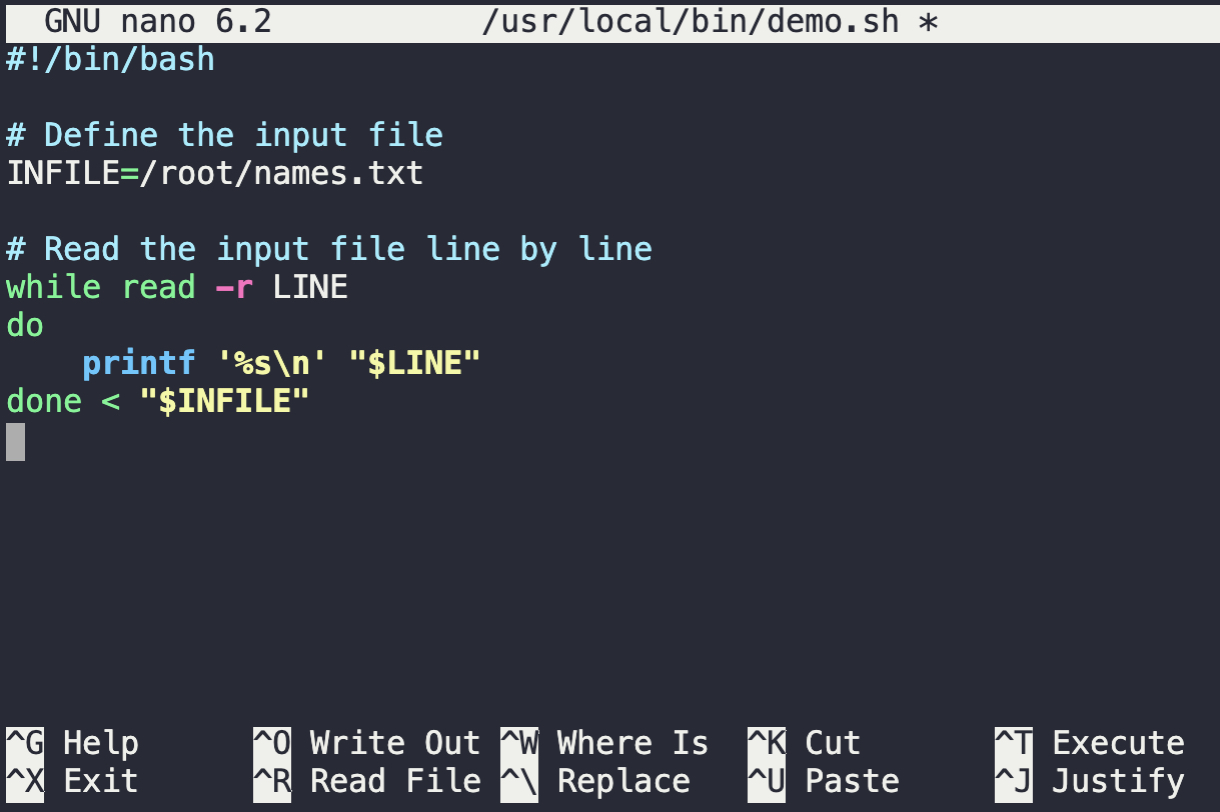
Once you've added the script, you'll need to save your work and exit the nano editor. To save, press ctrl + o. You'll see a message asking for the File Name to Write. Just press Enter to agree with the name that's already there. After your file is saved, you can leave nano by pressing ctrl + x.
Before we run this file, let's take a look at the script we've written:
#!/bin/bash: This is a shebang (#!), used to indicate that the script should be executed using the bash shell.INFILE=/root/names.txt: Here, we're creating a variable calledINFILEand assigning it the full path of thenames.txtfile. We need to provide the full path, as the file is not in the same directory as our script.while read -r LINE: This begins a while loop. Theread -r LINEcommand reads a single line from the input file. The-roption prevents backslashes in the input from being interpreted as escape characters. So if you have input likeHello\nWorld, without the-roption,readwould interpret this as two lines:HelloandWorld. If you use the-roption (read -r),readtreats backslashes as normal characters. SoHello\nWorldwould be interpreted as the literal stringHello\nWorld, not as two lines. TheLINEis a variable that holds the content of the line that's been read.
This pattern is known as the classic bash while read loop, and it remains the safest way to process files of any size.
printf '%s\n' "$LINE": This is what happens inside the loop. For each line that's read from the file, the script executes theprintfcommand. Theprintf '%s\n' "$LINE"command prints the content of theLINEvariable followed by a newline (\n).%sis a placeholder that gets replaced with the value ofLINE.done < "$INFILE": This marks the end of the while loop. The< "$INFILE"part tells the shell that the read command inside the loop should take its input from the file namednames.txt(the value of the "INFILE" variable).
This approach is considered the safest and most memory-efficient way to bash read file line by line, especially for large files. The pattern is often referred to as the classic bash while read loop, widely used in production automation.
Now that we've gone through what the script does, it's time to run it. To do this, run the following command:
bash demo.shYou should see each line from the names.txt file printed in the terminal on its own line, like this:

Reading a File Line By Line in Bash With a For Loop
You can also use a for loop to read the names.txt file line by line.
Replace the previous script in the demo.sh file with the following script. This new script uses a for loop to read each line from the names.txt file and print it to the terminal window:
#!/bin/bash
# Define the input file
INFILE=/root/names.txt
# Read the input file line by line using a for loop
IFS=$'\n' # set the Internal Field Separator to newline
for LINE in $(cat "$INFILE")
do
echo "$LINE"
doneBefore we run this, let's talk about what the script is doing:
IFS=$'\n': Here, we're setting the Internal Field Separator (IFS) to a newline ($'\n'). TheIFSis a special variable that tells the for loop what to split on. By settingIFSto a newline, we're making the for loop treat each line in thenames.txtfile as a separate item, even if there are spaces in the line.for LINE in $(cat "$INFILE"): This starts the for loop. The$(cat "$INFILE")command reads theINFILEand gives its contents to the for loop. The for loop goes through each line, treating each line as its own item and putting it in theLINEvariable.
An important point to note here is that the $(cat "$INFILE") part of the command is known as command substitution. What it does is, it runs the cat "$INFILE" command, which reads all the content of the file that INFILE points to, and then replaces $(cat "$INFILE") with that content. This means that before the for loop even starts, the whole file is already loaded into memory as a list for the for loop to process. This is why using a for loop can cause issues with very large files
However, this approach is sometimes used when you want to quickly bash read file into array variables or store all lines in a single variable for later use.
echo "$LINE": This is what the for loop does for each line. It uses theechocommand to show the contents of theLINEvariable, which is the current line from the file.
Keep in mind that for-loops can break lines that contain spaces unless handled carefully, so they’re not ideal when you need to bash read file with spaces exactly as written.
Now, let's run the script with the following command:
bash demo.shYou should see the lines from the names.txt file in the terminal, each on its own line, like this:
Explore more about this topic in this video
Master Linux with our Linux Learning Path:

Performance Tip: When working with huge datasets, always prefer the while-read method. This approach is significantly faster compared to using cat with loops - a comparison often referred to as cat vs while-read in the Bash community.Conclusion
In this post, we learned how to write Bash scripts that use while and for loops to read a file line by line.
If your file is small, you can use either a while loop or a for loop. But if your file is big, it's better to use a while loop. The while loop reads the file one line at a time, so it doesn't use a lot of memory. A for loop, however, reads the whole file at once, which can make things slower if the file is very big.
More on Linux:
- How to Boot or Change System Mode in Linux
- How to Force Reboot Linux from the Command Line
- How to Create a Soft Link in Linux
- How to Check if a File Exists in Bash
- How to Find Out When a File Was Created in Linux
- How to Read a File Line by Line in Bash
- How to Run Shell Script (.sh) Files in Linux
- How to Write Bash Scripts to Loop Through Array Values
- How to Count the Number of Files in a Directory in Linux
FAQs
Q1: Why does read -r matter so much when reading files?
Without -r, Bash interprets backslashes (\) as escape characters, which can alter the content of the line. If your file contains JSON, paths, or regex patterns, using read -r prevents unexpected interpretation or data loss.
Q2: Can I read a file line by line without using external commands like cat?
Yes!
The while-loop method:
while read -r line; do echo "$line"done < file.txt
does not require cat and is considered the most efficient and idiomatic Bash approach.
Q3: What happens if the file contains empty lines or spaces?
Using read -r preserves empty lines, and quoting variables ("$line") ensures leading/trailing spaces stay intact. For loops, however, often collapse whitespace, which is why they’re not reliable for sensitive data.
Q4: How can I handle files with millions of lines without memory issues?
Use a while-loop because it processes one line at a time. For loops are not recommended because they load the entire file into RAM, which can crash the shell with large files.
Q5: What if the file path contains spaces?
Always wrap variables in quotes:
INFILE="/path/with space/names.txt"while read -r line; do echo "$line"done < "$INFILE"
Without quotes, Bash splits the path at spaces and fails to locate the file.












Discussion