I was able to restore etcd from a snapshot.
However, the recovered pod (which was deleted earlier as a test) seem superficial.
As you can see from the screen-capture, the pod exist but trying to run a command in the pod returns an error that the pod doesn’t exist.
So what gives?
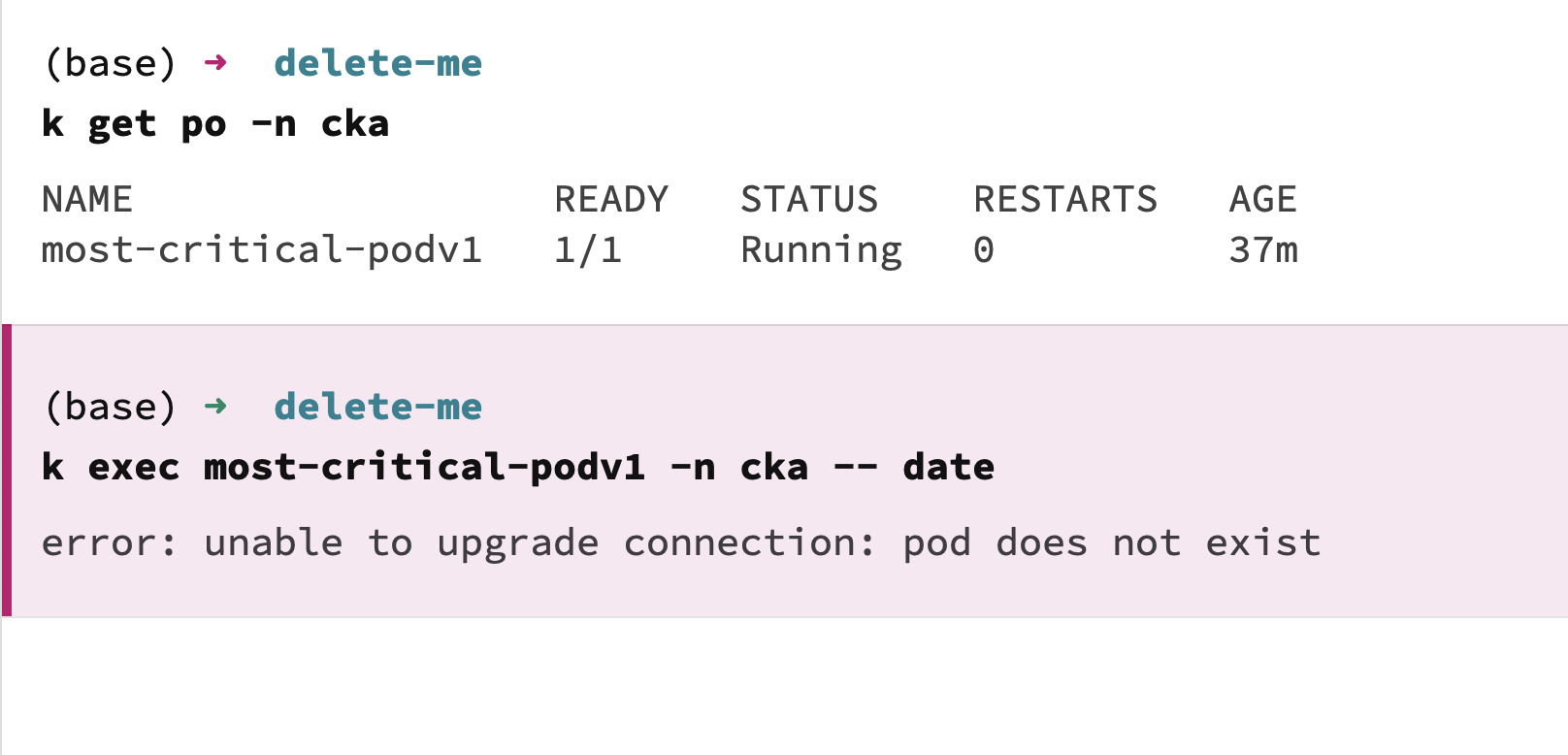
TBH I’m not sure what’s going on there. k get says the pod is there. What does “delete-me” do? If it deletes the pod, then all bets are off.
and just to prove i wasn’t smokin something that i’m not supposed to, here’s a screenshot from k9s where it recognizes the existence of the pod but streaming out the logs returns back an error that the pod cannot be found.

oh that’s just the name of the folder where i’m currently at… you can ignore that part
Still don’t know what’s up. If you run k describe po -o wide, what do you see now?
the details from the describe command makes one believe the pod is legit as you can from the output below but again it’s superficial as the info from the describe command is from the pod captured before the snapshot creation and got carried over after etcd was restored (clue: events shows 63m ago)… i tried restoring it again but same thing.
Name: most-critical-podv1
Namespace: cka
Priority: 0
Service Account: default
Node: worker-1/192.168.1.125
Start Time: Sat, 06 Apr 2024 09:45:24 +0800
Labels: run=most-critical-podv1
Annotations: <none>
Status: Running
IP: 10.0.1.7
IPs:
IP: 10.0.1.7
Containers:
most-critical-podv1:
Container ID: containerd://f6e75e7d2d0f9985860ef09dc07e94cd281f50ffb8f0771192ab2c20da429ed8
Image: nginx
Image ID: docker.io/library/nginx@sha256:6db391d1c0cfb30588ba0bf72ea999404f2764febf0f1f196acd5867ac7efa7e
Port: <none>
Host Port: <none>
State: Running
Started: Sat, 06 Apr 2024 09:45:27 +0800
Ready: True
Restart Count: 0
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-cvxp4 (ro)
Conditions:
Type Status
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-cvxp4:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 63m default-scheduler Successfully assigned cka/most-critical-podv1 to worker-1
Normal Pulling 63m kubelet Pulling image "nginx"
Normal Pulled 63m kubelet Successfully pulled image "nginx" in 2.410806133s (2.410810757s including waiting)
Normal Created 63m kubelet Created container most-critical-podv1
Normal Started 63m kubelet Started container most-critical-podv1
steps i did and how i managed to get myself into this predicament:
- create a pod named aptly most-critical-podv1
- create an etcd snapshot
- delete the pod
- restore etcd from the snapshot
- test if deleted pod was recovered from the restored snapshot by running a command inside the pod
if you have bandwidth at the moment, can you try recreate this simple step from your end and confirm if pod is indeed alive?
Can’t really do the whole process. And you have something weird here – I doubt I’d replicate what’s causing the weirdness. So here’s some things to try:
-
k -n cka get po most-critical-podv1 -o wide, to get the node. - ssh THE-NODE
-
crictl ps | grep most-critical-podv1to make sure the container actually exists on the node. - exit
-
k -n cka get po most-critical-podv1 -o yaml > mcp.yamlto see if you get something that makes sense.
If all of these things work, the question is why exec does not work, because as we say in US English, if it walks like a duck, and talks like a duck, it’s a… duck.
well well well, lo and behold, the issue is also manifested in the practice exam… was able to restore the damn thing but its also superficial and the practice exam makes you believe the restoration is all well and good but as you can see in the screenshot, it’s the same error i was getting in my local environment. the deployment now exists and the pod shows it is running after etcd restoration but trying to run a command in one of the pods errors out with “does not exist”!
… so there must be another step missing here e.g., rollout-restart all deployments after restoration? I can see how that would work but what about stand-alone pods, there’s no way to restart it unless you generate and re-create from a manifest yaml file but that defeats the objective of what the backup and restore of etcd was all about?
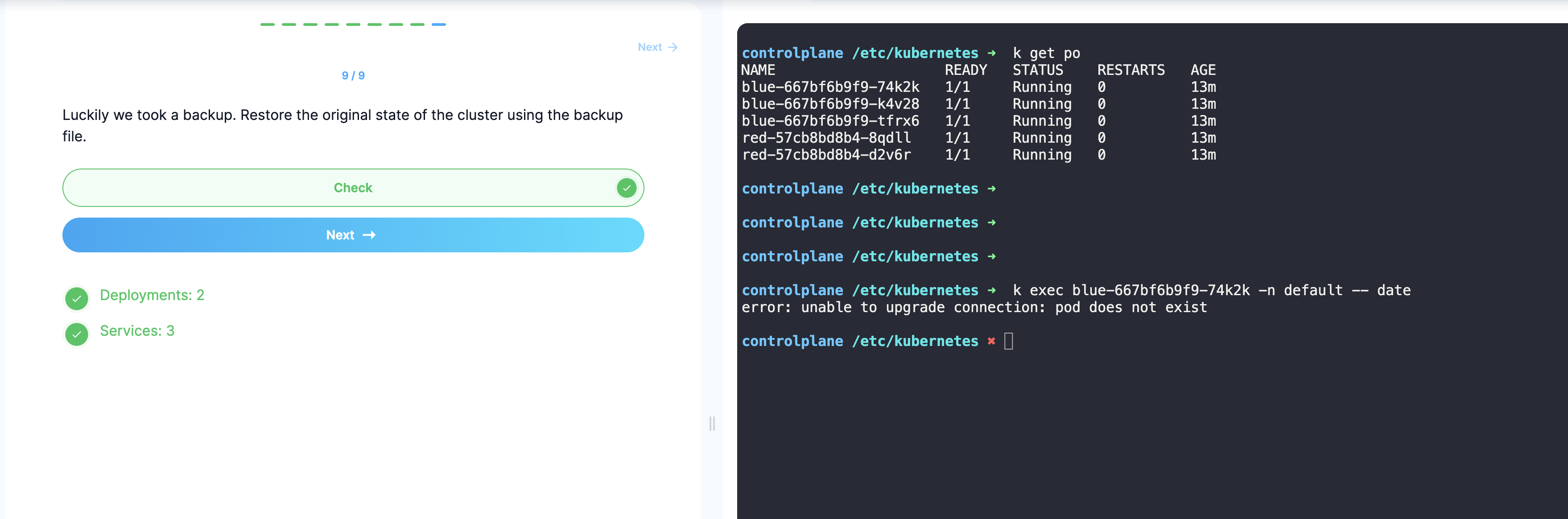
no need to do the whole process, can easily be reproduced from the practice exam as you can see from previous post before this