Hi All,
Can you please share any reference documentation to setup Kubernetes cluster setup (1 master, 2 worker nodes) using virtual box and kubeadm locally.
Hi All,
Can you please share any reference documentation to setup Kubernetes cluster setup (1 master, 2 worker nodes) using virtual box and kubeadm locally.
We have several here
Hi @Alistair_KodeKloud , Thanks for your reply.
I have setup my local cluster using VirtualBox and Kubeadm as described from mentioned steps.
I am getting below error when finished all steps and trying to run kubectl commands.
I tried after of restart of conainerd/kubelet services, still same issue.
Appreciate if you can help me on this. Thanks.
Error details:
vagrant@kubemaster:~$ kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://192.168.56.11:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
vagrant@kubemaster:~$
vagrant@kubemaster:~$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
* kubernetes-admin@kubernetes kubernetes kubernetes-admin
vagrant@kubemaster:~$
vagrant@kubemaster:~$ kubectl get all -A
E1224 06:50:22.673289 121446 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:50:22.674370 121446 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:50:22.674909 121446 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:50:22.676283 121446 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:50:22.676471 121446 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
The connection to the server 192.168.56.11:6443 was refused - did you specify the right host or port?
vagrant@kubemaster:~$
vagrant@kubemaster:~$ kubectl get nodes
E1224 06:56:55.263061 124948 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:56:56.051358 124948 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:56:56.052674 124948 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:56:56.053408 124948 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
E1224 06:56:56.055039 124948 memcache.go:265] couldn't get current server API group list: Get "https://192.168.56.11:6443/api?timeout=32s": dial tcp 192.168.56.11:6443: connect: connection refused
The connection to the server 192.168.56.11:6443 was refused - did you specify the right host or port?
vagrant@kubemaster:~$
vagrant@kubemaster:~$
vagrant@kubemaster:~$ kubectl cluster-info
Kubernetes control plane is running at https://192.168.56.11:6443
CoreDNS is running at https://192.168.56.11:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
vagrant@kubemaster:~$
I have just re-tested it
vagrant@kubemaster:~$ kubectl get no
NAME STATUS ROLES AGE VERSION
kubemaster Ready control-plane 97s v1.29.0
kubenode01 Ready <none> 25s v1.29.0
kubenode02 Ready <none> 16s v1.29.0
vagrant@kubemaster:~$ date
Sun Dec 24 08:18:05 UTC 2023
and as you can see, it is running fine.
What do you see if you run the following on kubemaster?
sudo crictl ps
If numbers in the ATTEMPTS column are more than zero for any of the kube components or etcd, then you have missed something because it means the control plane pods are crashlooping.
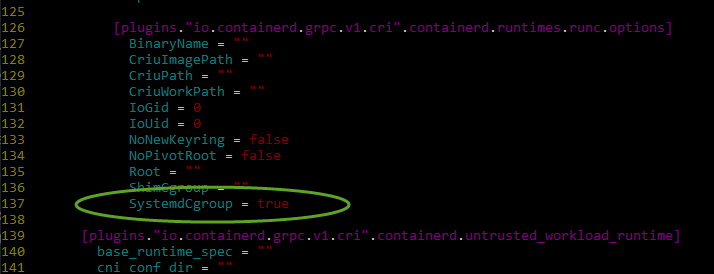
Step 6 on this page is very important to get right or the pods will definitely crashloop
You can also follow these steps to determine why a control plane pod is crashing.
Vagrant@controlplane:~$ kubectl get pods -A The connection to the server 192.168.29.105:6443 was refused - did you specify the right host or port? . Please can you help me with this ? I have tried everythig