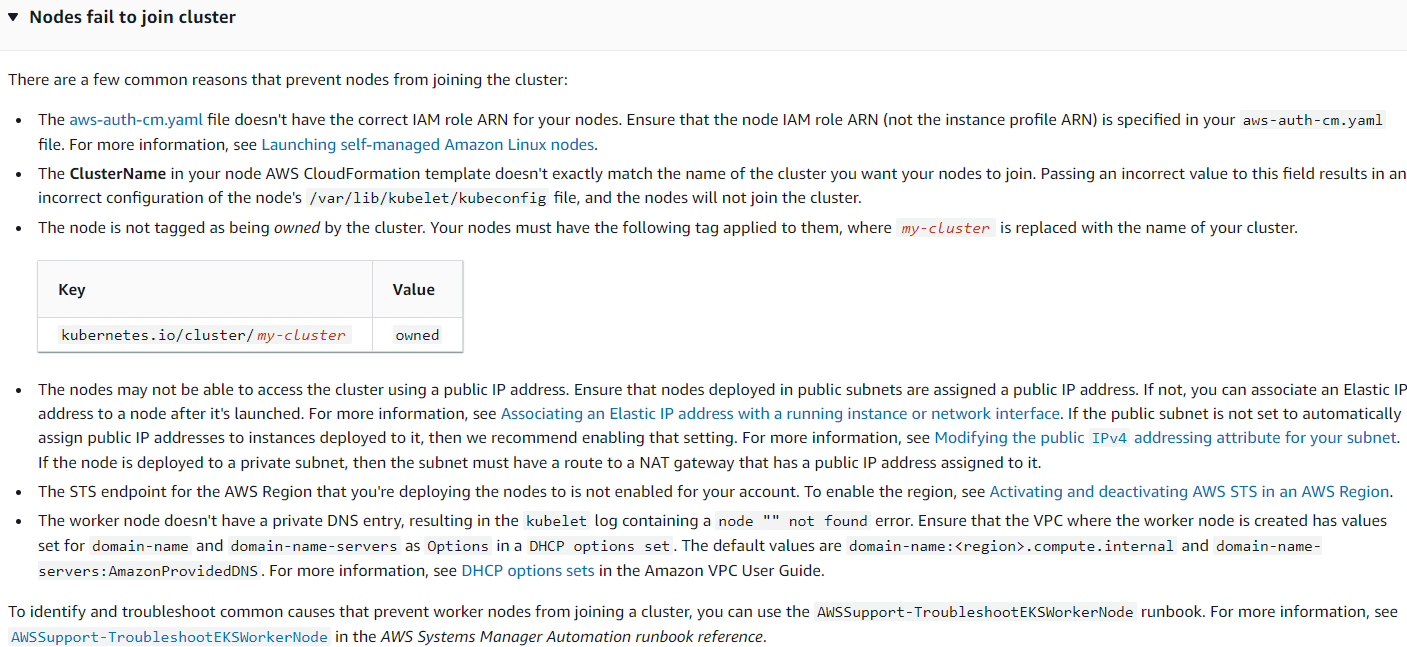
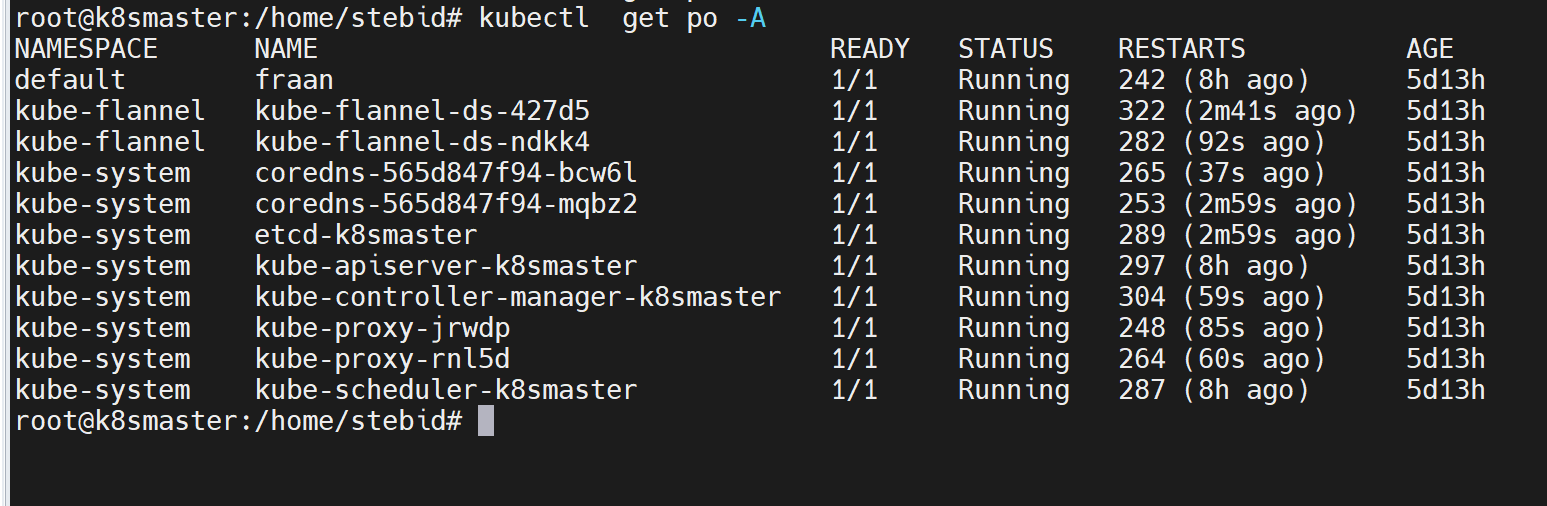
Stanislaus Tebid:
I setup a new K8 cluster on AWS. 1 controlplane and one worker node. the api servers seems to be crashing all the time and so I cannot run kubectl commands.
root@k8smaster:/home/stebid# tail -f /var/log/syslog
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.741029 351421 status_manager.go:667] "Failed to get status for pod" podUID=cd890ac3-fd7a-4cf8-9049-1970b457154a pod="kube-flannel/kube-flannel-ds-427d5" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-flannel/pods/kube-flannel-ds>
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.741319 351421 status_manager.go:667] "Failed to get status for pod" podUID=6d4cfb01-b333-4da3-b02c-9b8dcfa2c015 pod="kube-system/kube-proxy-rnl5d" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/kube-proxy-rnl5d>\": di
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.741566 351421 status_manager.go:667] "Failed to get status for pod" podUID=d7975323-ae24-4fbf-9200-4f6151cfaf8a pod="kube-system/coredns-565d847f94-mqbz2" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/coredns-565d84>
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.741766 351421 status_manager.go:667] "Failed to get status for pod" podUID=6f942e11-36a1-46c1-be68-a1839095961f pod="kube-system/coredns-565d847f94-bcw6l" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/coredns-565d84>
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.741992 351421 status_manager.go:667] "Failed to get status for pod" podUID=d0a0bddb4a42b86747a19ed468c8489f pod="kube-system/kube-apiserver-k8smaster" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/kube-apiserver-k8s>
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.742202 351421 status_manager.go:667] "Failed to get status for pod" podUID=d8a05715cccde8d24d9685d9f9a09c4d pod="kube-system/etcd-k8smaster" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/etcd-k8smaster>\": dial tcp 1
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.742395 351421 status_manager.go:667] "Failed to get status for pod" podUID=fa88f8c1fcc79cf2a8d18ff6a2fa092d pod="kube-system/kube-controller-manager-k8smaster" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/kube-cont>
Nov 17 22:27:44 k8smaster kubelet[351421]: I1117 22:27:44.742593 351421 status_manager.go:667] "Failed to get status for pod" podUID=09e81d8bc9bd7ceccc1e0bfc16b2f4fa pod="kube-system/kube-scheduler-k8smaster" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/kube-scheduler-k8s>
Nov 17 22:27:45 k8smaster kubelet[351421]: I1117 22:27:45.741084 351421 scope.go:115] "RemoveContainer" containerID="601118cc72ad69c268147e0223b42d216f3c6cffdeeb5e22f5543b7563a95dee"
Nov 17 22:27:45 k8smaster kubelet[351421]: E1117 22:27:45.741674 351421 pod_workers.go:965] "Error syncing pod, skipping" err="failed to \"StartContainer\" for \"kube-flannel\" with CrashLoopBackOff: \"back-off 5m0s restarting failed container=kube-flannel pod=kube-flannel-ds-427d5_kube-flannel(cd89
Nov 17 22:27:48 k8smaster kubelet[351421]: E1117 22:27:48.142264 351421 event.go:276] Unable to write event: '&v1.Event{TypeMeta:v1.TypeMeta{Kind:"", APIVersion:""}, ObjectMeta:v1.ObjectMeta{Name:"kube-apiserver-k8smaster.17287c12afa20fbf", GenerateName:"", Namespace:"kube-system", SelfLink:"", UID:ring(nil), ManagedFields:[]v1.ManagedFieldsEntry(nil)}, InvolvedObject:v1.ObjectReference{Kind:"Pod", Namespace:"kube-system", Name:"kube-apiserver-k8smaster", UID:"d0a0bddb4a42b86747a19ed468c8489f", APIVersion:"v1", ResourceVersion:"", FieldPath:"spec.containers{kube-apiserver}"}, Reason:"BackOff", tTime:time.Date(1, time.January, 1, 0, 0, 0, 0, time.UTC), Series:(*v1.EventSeries)(nil), Action:"", Related:(*v1.ObjectReference)(nil), ReportingController:"", ReportingInstance:""}': 'Patch "<https://192.168.1.230:6443/api/v1/namespaces/kube-system/events/kube-apiserver-k8smaster.17287c12afa20fbf>":
Nov 17 22:27:50 k8smaster kubelet[351421]: I1117 22:27:50.446726 351421 status_manager.go:667] "Failed to get status for pod" podUID=09e81d8bc9bd7ceccc1e0bfc16b2f4fa pod="kube-system/kube-scheduler-k8smaster" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/kube-scheduler-k8s>
Nov 17 22:27:50 k8smaster kubelet[351421]: E1117 22:27:50.523585 351421 controller.go:144] failed to ensure lease exists, will retry in 7s, error: Get "<https://192.168.1.230:6443/apis/coordination.k8s.io/v1/namespaces/kube-node-lease/leases/k8smaster?timeout=10s>": dial tcp 192.168.1.230:6443: connec
Nov 17 22:27:51 k8smaster kubelet[351421]: I1117 22:27:51.203532 351421 status_manager.go:667] "Failed to get status for pod" podUID=09e81d8bc9bd7ceccc1e0bfc16b2f4fa pod="kube-system/kube-scheduler-k8smaster" err="Get \"<https://192.168.1.230:6443/api/v1/namespaces/kube-system/pods/kube-scheduler-k8s>
Nov 17 22:27:53 k8smaster kubelet[351421]: E1117 22:27:53.660449 351421 kubelet_node_status.go:460] "Error updating node status, will retry" err="error getting node \"k8smaster\": Get \"<https://192.168.1.230:6443/api/v1/nodes/k8smaster?resourceVersion=0&timeout=10s>\": dial tcp 192.168.1.230:6443: co
Nov 17 22:27:53 k8smaster kubelet[351421]: E1117 22:27:53.660659 351421 kubelet_node_status.go:460] "Error updating node status, will retry" err="error getting node \"k8smaster\": Get \"<https://192.168.1.230:6443/api/v1/nodes/k8smaster?timeout=10s>\": dial tcp 192.168.1.230:6443: connect: connection
Nov 17 22:27:53 k8smaster kubelet[351421]: E1117 22:27:53.660812 351421 kubelet_node_status.go:460] "Error updating node status, will retry" err="error getting node \"k8smaster\": Get \"<https://192.168.1.230:6443/api/v1/nodes/k8smaster?timeout=10s>\": dial tcp 192.168.1.230:6443: connect: connection
Nov 17 22:27:53 k8smaster kubelet[351421]: E1117 22:27:53.660960 351421 kubelet_node_status.go:460] "Error updating node status, will retry" err="error getting node \"k8smaster\": Get \"<https://192.168.1.230:6443/api/v1/nodes/k8smaster?timeout=10s>\": dial tcp 192.168.1.230:6443: connect: connection
Nov 17 22:27:53 k8smaster kubelet[351421]: E1117 22:27:53.661139 351421 kubelet_node_status.go:460] "Error updating node status, will retry" err="error getting node \"k8smaster\": Get \"<https://192.168.1.230:6443/api/v1/nodes/k8smaster?timeout=10s>\": dial tcp 192.168.1.230:6443: connect: connection
Nov 17 22:27:53 k8smaster kubelet[351421]: E1117 22:27:53.661156 351421 kubelet_node_status.go:447] "Unable to update node status" err="update node status exceeds retry count"
Nov 17 22:27:53 k8smaster kubelet[351421]: I1117 22:27:53.741038 351421 scope.go:115] "