Amel ECHEIKH EZAOUALI:
Hello, i restored the etcd backup without any error message but when i check the object in system namespace i get the message No resources found in kube-system namespace. I followed the steps described here https://github.com/mmumshad/kubernetes-the-hard-way/blob/master/practice-questions-answers/cluster-maintenance/backup-etcd/etcd-backup-and-restore.md|https://github.com/mmumshad/kubernetes-the-hard-way/blob/master/practice-questions[…]wers/cluster-maintenance/backup-etcd/etcd-backup-and-restore.md
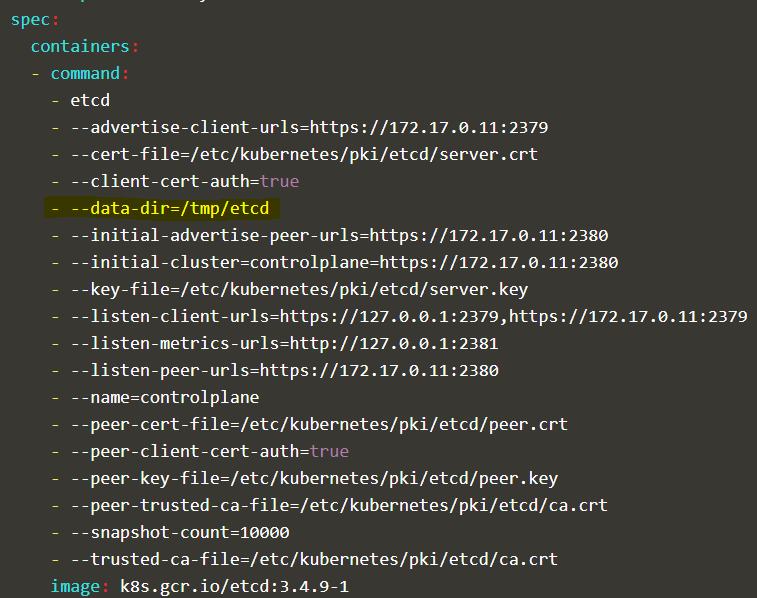

sreenivas:
hi Amel, i gues you are missing certs in snapshots save and restore. please refer to https://kodekloud.slack.com/archives/CHMV3P9NV/p1606697073438200
Amel ECHEIKH EZAOUALI:
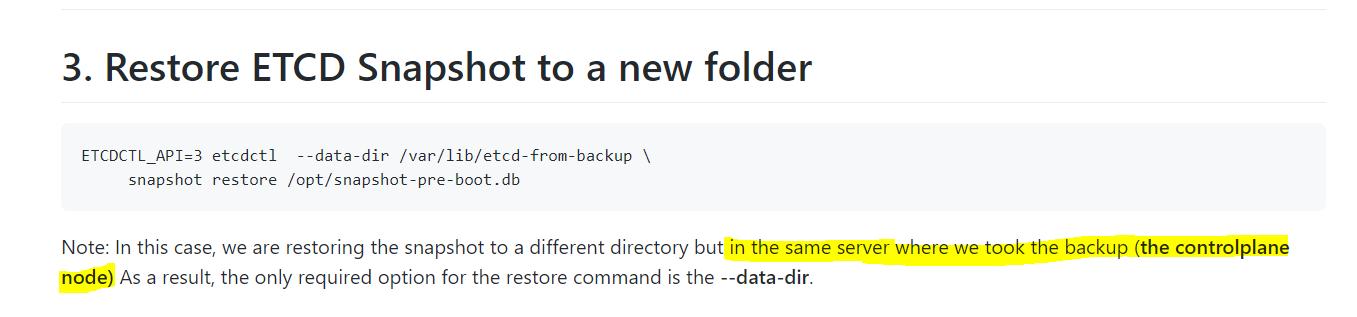
thanks but the certificates are not mandatory in case the restore is done on the same server that runs etcd pod
Md Ishaq R:
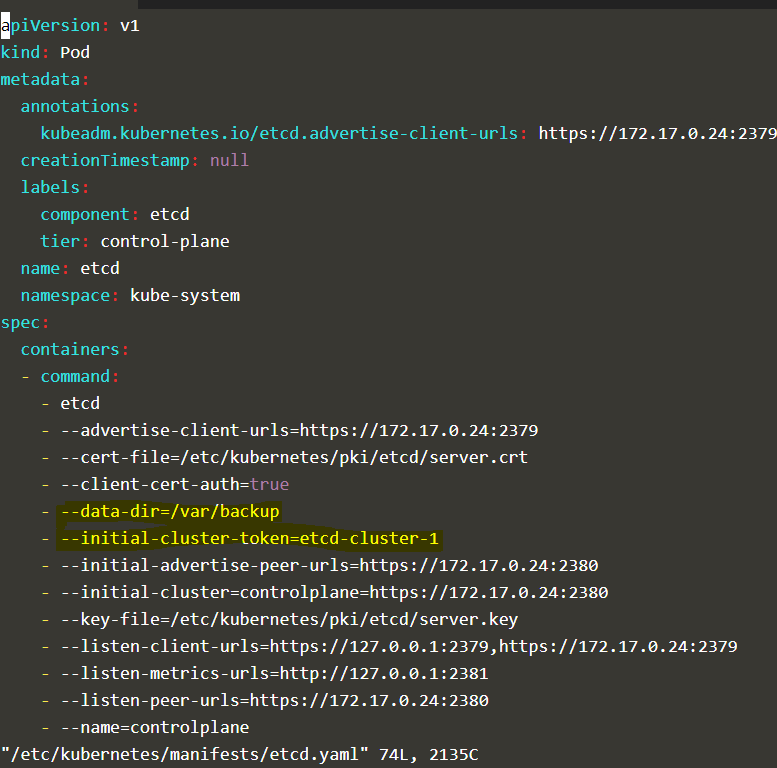
@Amel ECHEIKH EZAOUALI i think you are missing on the --initial-cluster-token=“etcd-cluster-1” in the etcd.yaml file
OE:
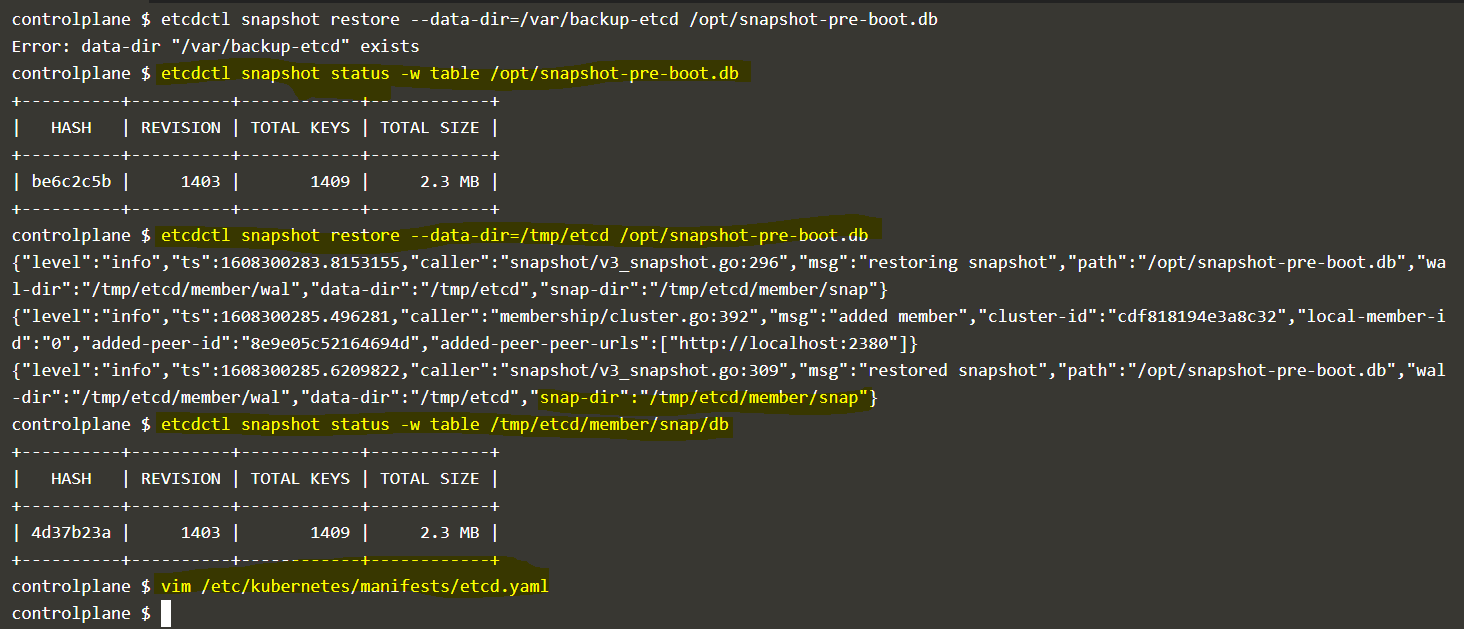
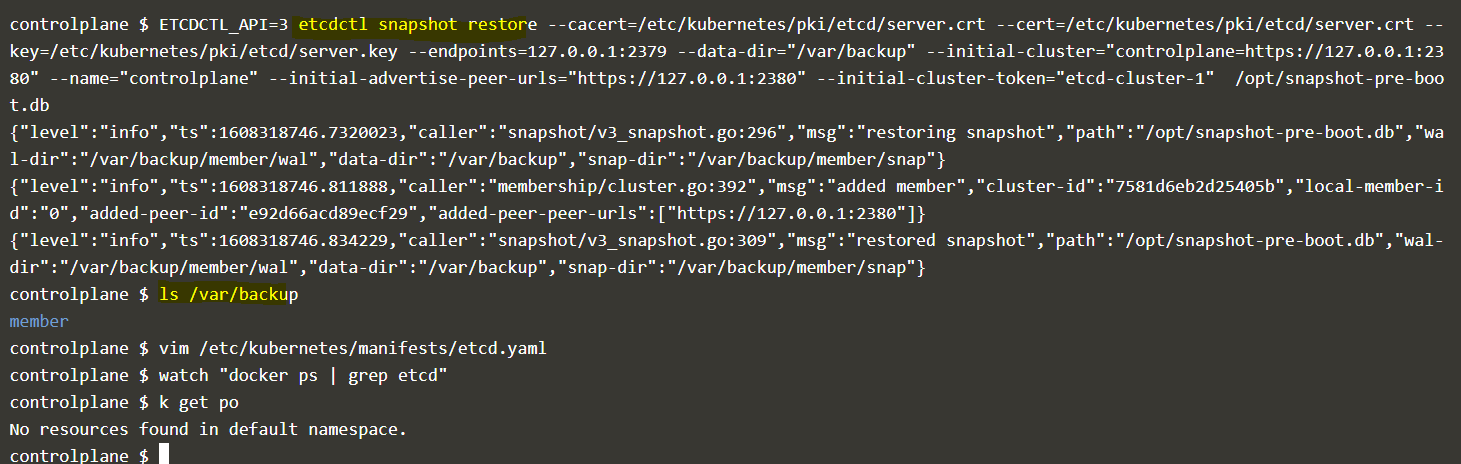
It gives you an error in your first screenshot. You can’t use --data-dir with a directory that already exists. Correct that. You also need the certs

Amel ECHEIKH EZAOUALI:
Subhijith Tharayil:
The --cacert is pointing to server.crt. It should point to */ca.crt in the snapshot save
1. Backup
During backup process you will need to provide the certificates for authentication purposes, like it says in the docs: Operating etcd clusters for Kubernetes | Kubernetes
--cacert=<trusted-ca-file> --cert=<cert-file> --key=<key-file> \
You can actually provide either the apiserver certificate & key pair or server certificate & key pair. In both cases it works fine, creating the same backup.
2. Restore
Note from the docs (k8s, same as above)
If any API servers are running in your cluster, you should not attempt to restore instances of etcd. Instead, follow these steps to restore etcd:
- stop all API server instances
- restore state in all etcd instances
- restart all API server instances
So first stop the API.
Secondly, there is a bit of missconception about the ETCD restore command. Following the ETCD docs: Disaster recovery | etcd
A cluster restore with
etcdctl snapshot restorecreates new etcd data directories
So I guess where I was confused, providing an IP or CERTS does not “load the backup db INTO existing server/cluster”. IT WILL CREATE THE DIRECTORIES ANYWAY!
Now, because you were creating the backup with the very same settings and you are not chaning anything on the “new etcd” instance, you’ll be fine with just:
etcdctl snapshot restore /tmp/etcd-backup.db --data-dir /var/lib/etcd-backup
However, the risk is that IF the backup was created with OTHER certificates or settings, then you’d need to provide them manually in the command.
3. The error from the thread
I had the very same issue and I just could not get my head around what is going on. I have tested all the above back and forth, yet all my cluster components were gone after the restore.
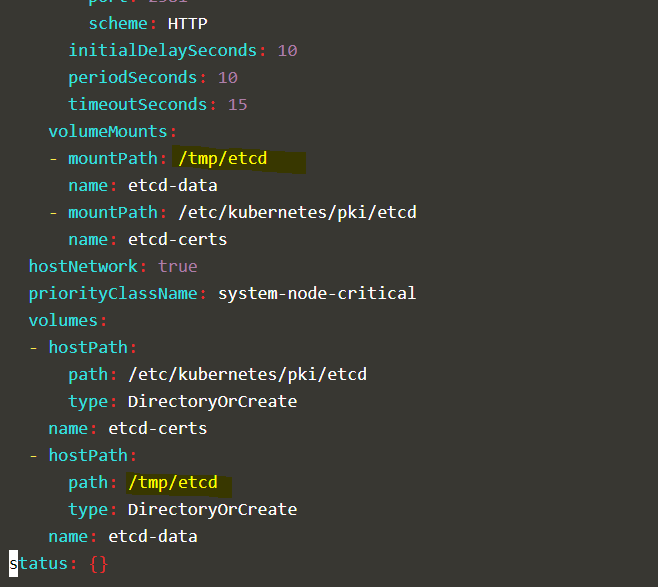
The issue was that I was modyfing wrong path in etcd.yaml configuration.
I was constantly providing the new path in the parameter:
---data-dir=/var/lib/etcd-backup
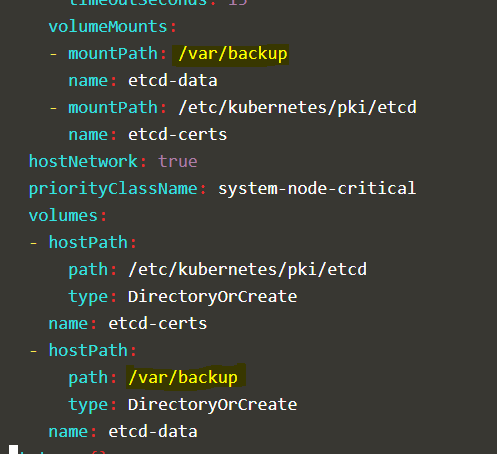
while I should have changed the MOUNT directory
- hostPath:
path: /var/lib/etcd-backup
type: DirectoryOrCreate
name: etcd-data
Oh, ffs, this took me way longer than expected.
Some notes on your notes:
-
trusted-ca-file- Must be the CA certificate used by etcd server. In some clusters this can be the same as used by API server, but usually it is not. etcd CA is found in/etc/kubernetes/pki/etcd
cert-file- Must be a certificate that was signed by the above CA. Any in/etc/kubernetes/pki/etcdshould normally work.
key-file- Must be the key asociated withcert-file -
snapshot restorecommand as you have given it, and as would be required for single node clusters does not communicate with API server or etcd server in any way, hence no certs. It isn’t necessary to stop any components here when writing to a newdata-dir. All this command does in this form is to create files in the directory indicated with--data-dir. - Absolutely! the restore command creates files in the filesystem of the node, not of the container. Thus you must update the
hostPathin thevolumesdeclaration- and that’s the only change needed! As soon as you save that change, kubelet will restart etcd for you and everything will be dandy!
Bottom line for single control plane clusters as found in the labs and exam, you don’t need to stop anything to do a restore (will cost you more time). Stopping stuff is really only required when dealing with multi-control node clusters, or trying to restore to the same data-dir that the original database was in.
1 Like