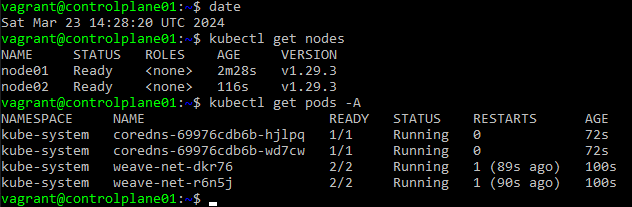
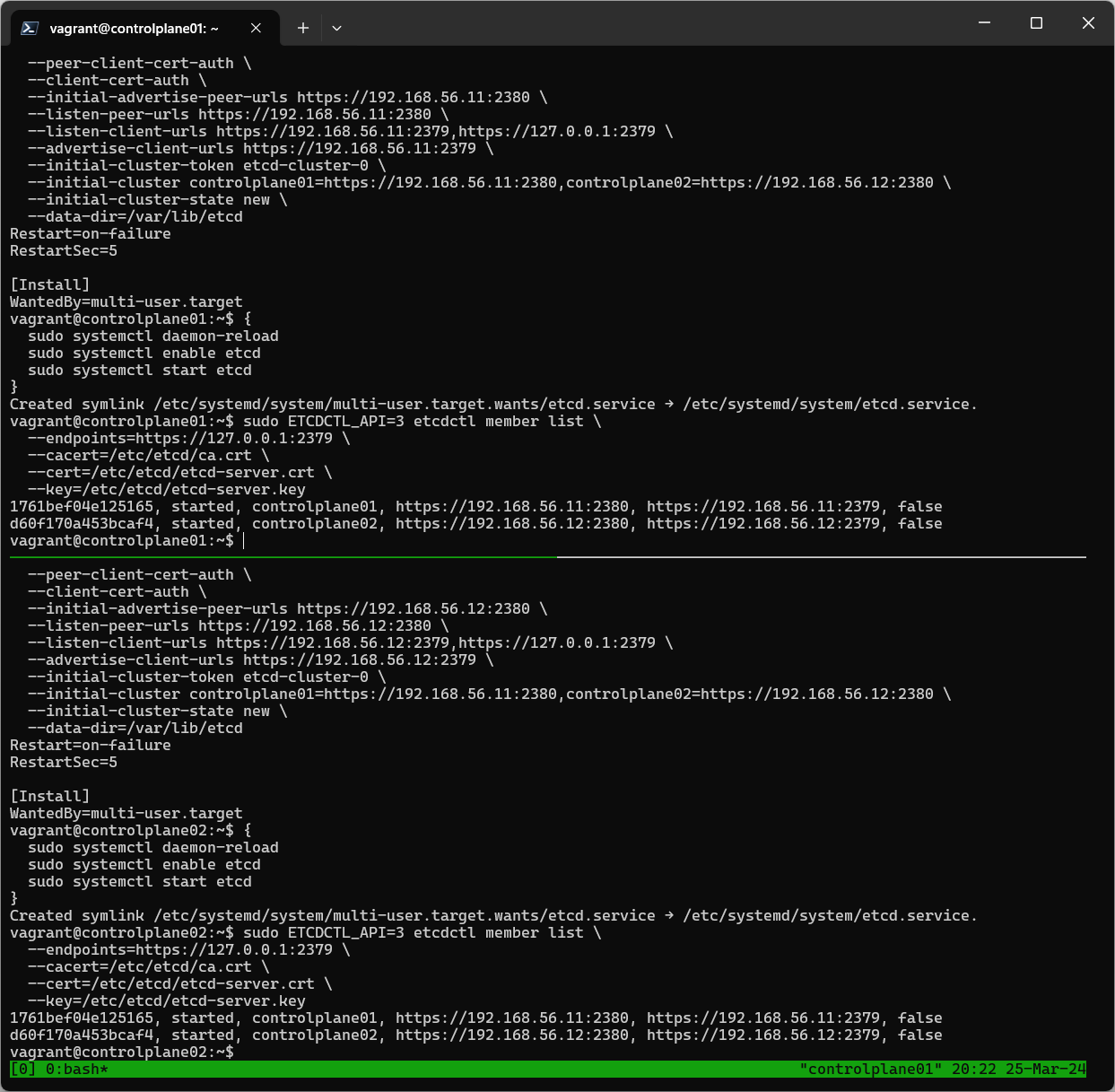
I retried multiple times. And everytime failed at the very same step.
Then tried to debug the etcd.service . To do that I started etcd and got the error printed on screen when running the etcd service. It keeps on saying bind address already in use.
How do I solve that??
Also let me know what is the importance of this step and possibly why this binding is not getting completed.
{"level":"warn","ts":"2024-03-25T12:42:43.961996Z","caller":"embed/config.go:673","msg":"Running http and grpc server on single port. This is not recommended for production."}
{"level":"info","ts":"2024-03-25T12:42:43.965189Z","caller":"etcdmain/etcd.go:73","msg":"Running: ","args":["etcd"]}
{"level":"warn","ts":"2024-03-25T12:42:43.967418Z","caller":"etcdmain/etcd.go:105","msg":"'data-dir' was empty; using default","data-dir":"default.etcd"}
{"level":"warn","ts":"2024-03-25T12:42:43.967547Z","caller":"embed/config.go:673","msg":"Running http and grpc server on single port. This is not recommended for production."}
{"level":"info","ts":"2024-03-25T12:42:43.967568Z","caller":"embed/etcd.go:127","msg":"configuring peer listeners","listen-peer-urls":["http://localhost:2380"]}
{"level":"info","ts":"2024-03-25T12:42:43.967985Z","caller":"embed/etcd.go:135","msg":"configuring client listeners","listen-client-urls":["http://localhost:2379"]}
{"level":"info","ts":"2024-03-25T12:42:43.968126Z","caller":"embed/etcd.go:376","msg":"closing etcd server","name":"default","data-dir":"default.etcd","advertise-peer-urls":["http://localhost:2380"],"advertise-client-urls":["http://localhost:2379"]}
{"level":"info","ts":"2024-03-25T12:42:43.968158Z","caller":"embed/etcd.go:378","msg":"closed etcd server","name":"default","data-dir":"default.etcd","advertise-peer-urls":["http://localhost:2380"],"advertise-client-urls":["http://localhost:2379"]}
{"level":"warn","ts":"2024-03-25T12:42:43.968182Z","caller":"etcdmain/etcd.go:146","msg":"failed to start etcd","error":"listen tcp 127.0.0.1:2379: bind: address already in use"}
{"level":"fatal","ts":"2024-03-25T12:42:43.968219Z","caller":"etcdmain/etcd.go:204","msg":"discovery failed","error":"listen tcp 127.0.0.1:2379: bind: address already in use","stacktrace":"go.etcd.io/etcd/server/v3/etcdmain.startEtcdOrProxyV2\n\tgo.etcd.io/etcd/server/v3/etcdmain/etcd.go:204\ngo.etcd.io/etcd/server/v3/etcdmain.Main\n\tgo.etcd.io/etcd/server/v3/etcdmain/main.go:40\nmain.main\n\tgo.etcd.io/etcd/server/v3/main.go:31\nruntime.main\n\truntime/proc.go:250"}
Also there is unrelated piece when I inspect the Virtual Box VMs another error whether genuine or not is noticed-