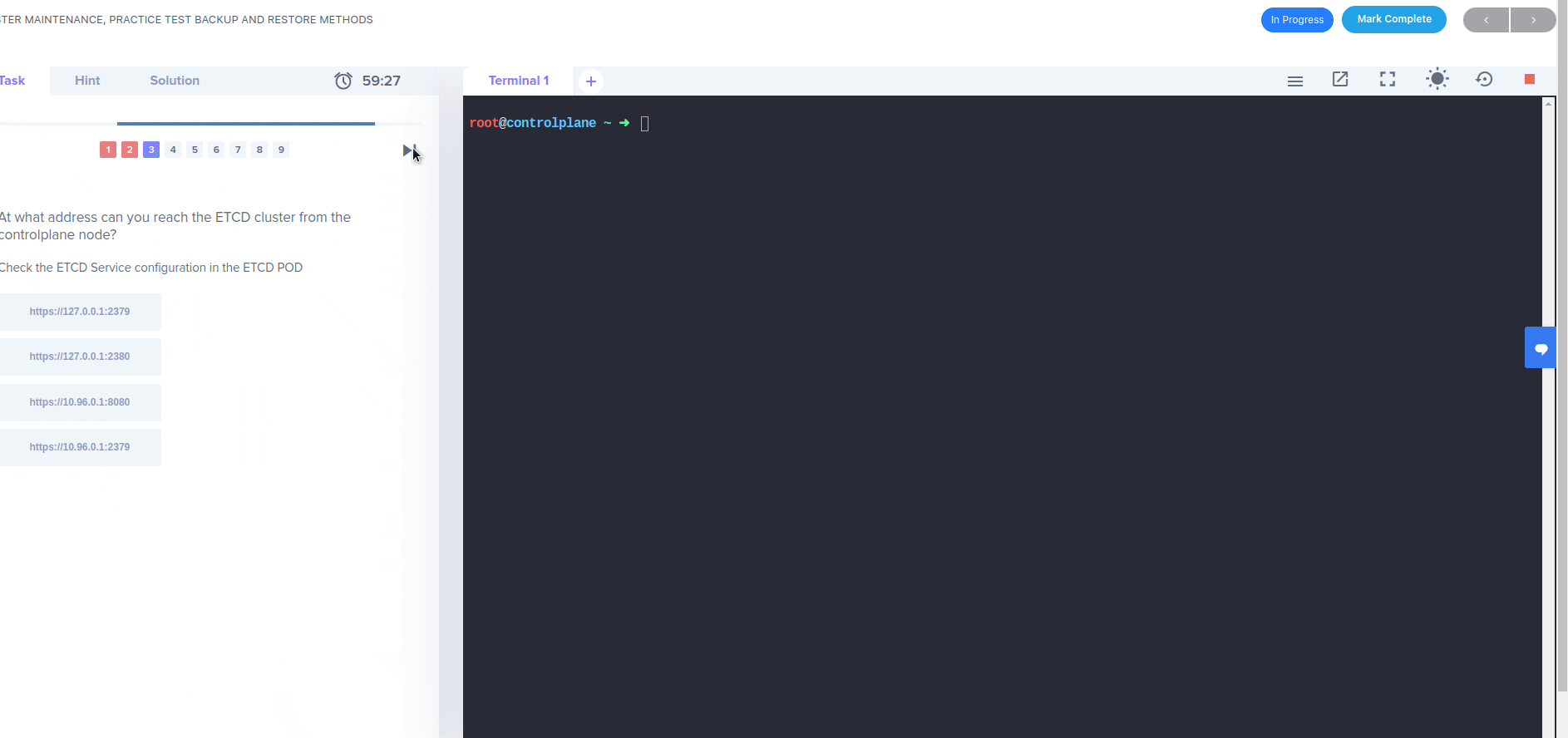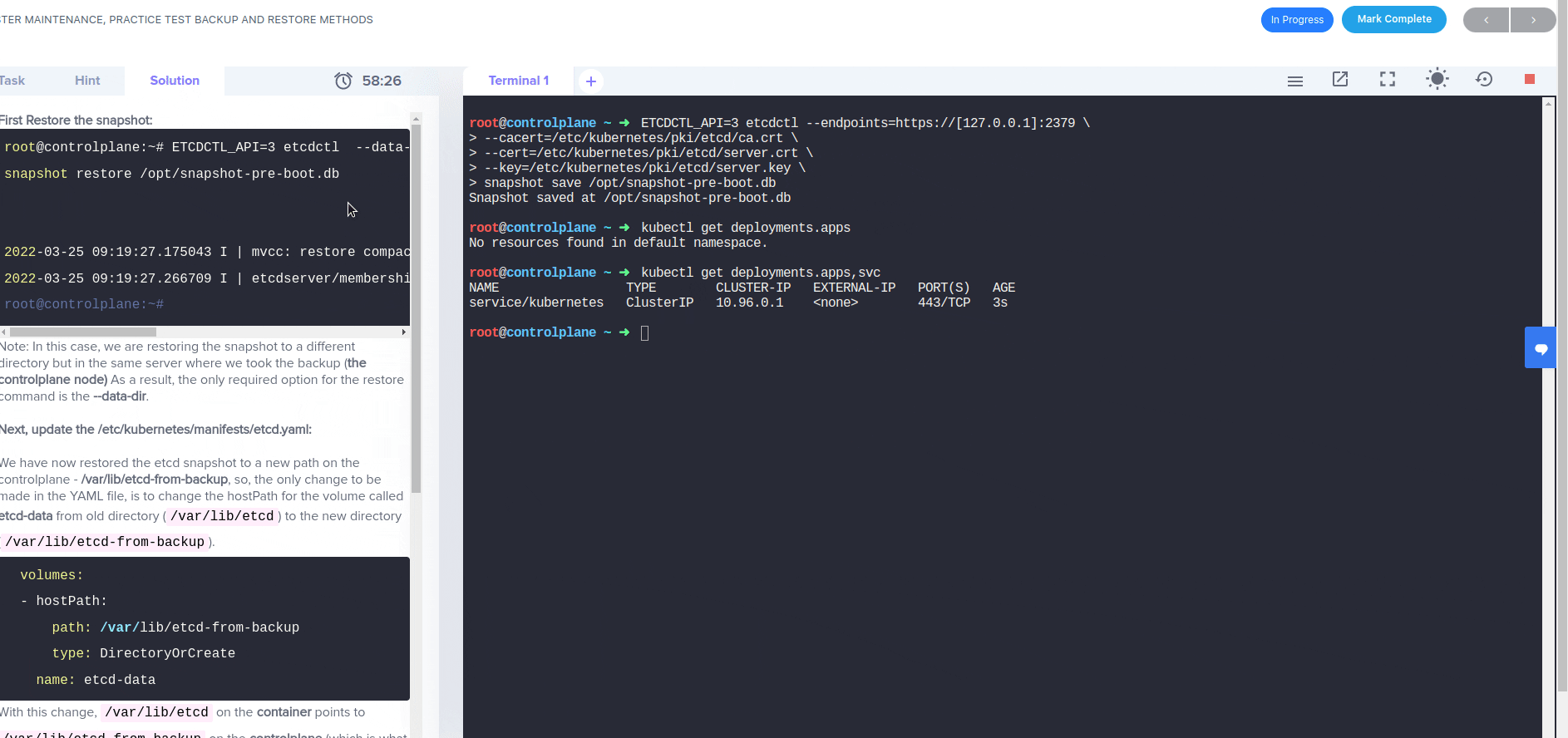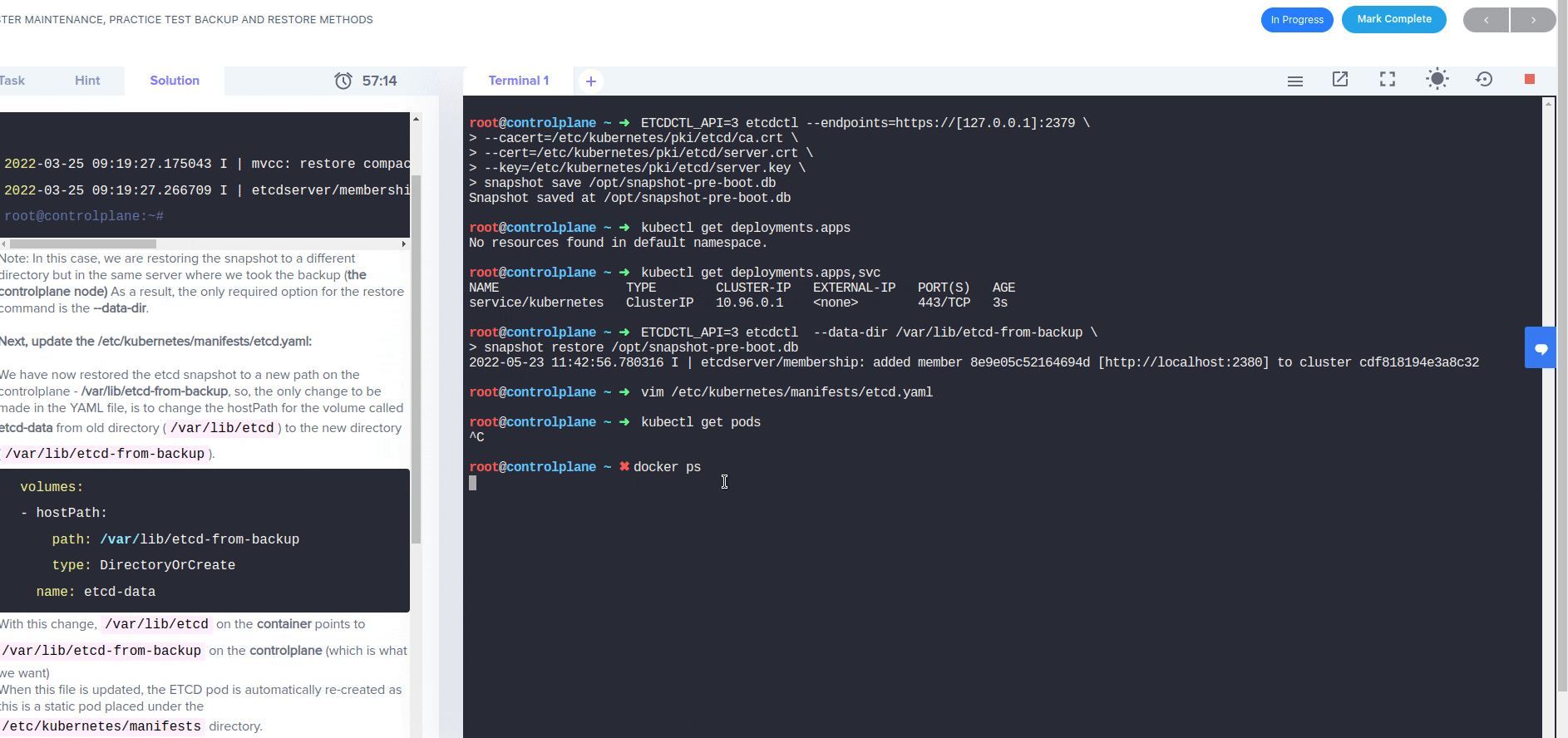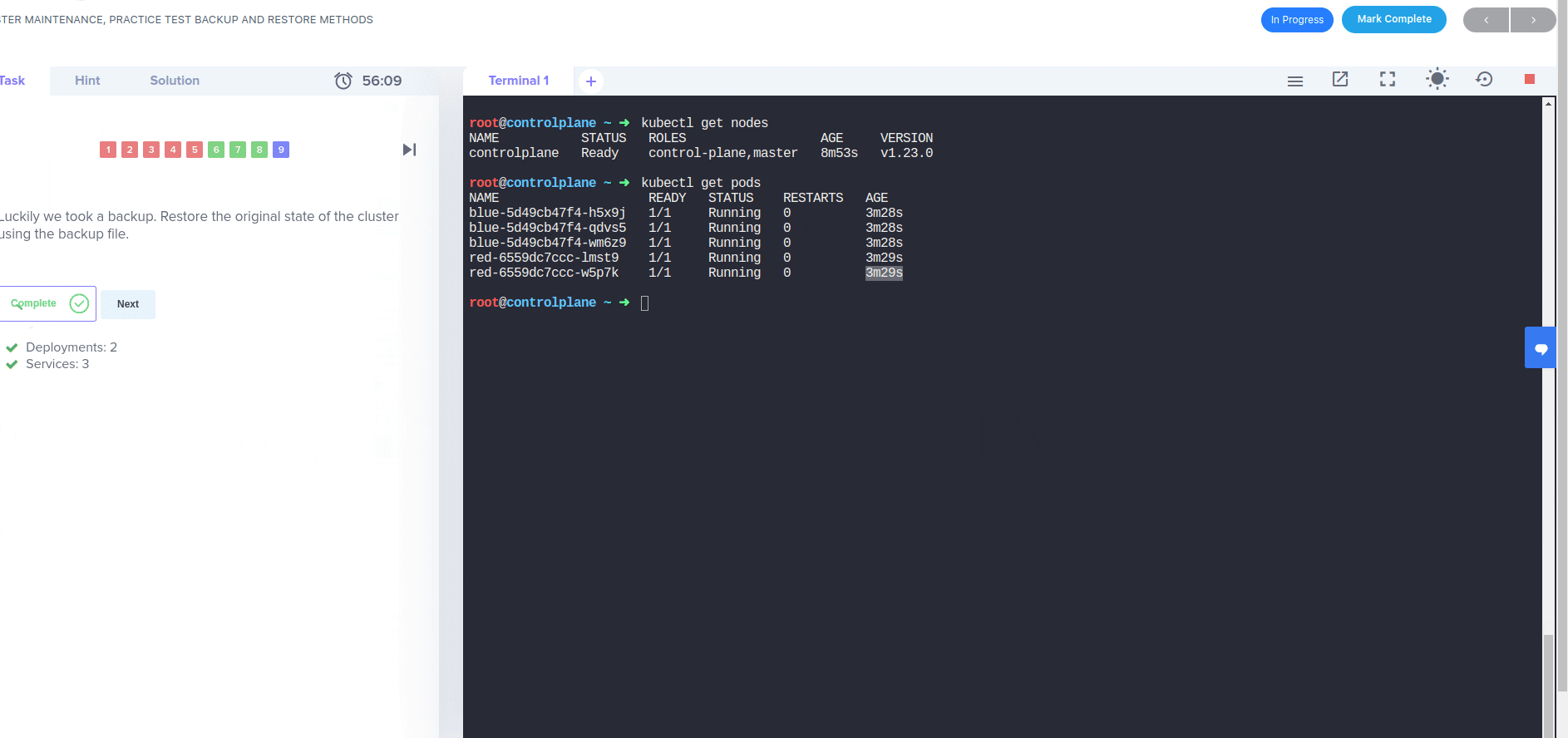
Hello,
I was attempting the CKA labs in the " Udemy Labs - Certified Kubernetes Administrator with Practice Tests" course. This issue is specifically for the “PRACTICE TEST BACKUP AND RESTORE METHODS” lab under Cluster Maintenance. On the final section, where I am supposed to restore etcd, kubectl fails to start up again after modifying the etcd.yaml file. After a couple of minutes, I keep getting this repeating error when I run any kubectl command:
The connection to the server controlplane:6443 was refused - did you specify the right host or port?)
I modified the etcd.yaml file by setting the etcd-date volume location to /var/lib/etcd-from-backup. This is also the data-dir that I specified when running ‘etcdctl snapshot restore’. Eventually, I gave up, restarted the lab, and tried following the given solution in the Solution tab. However, after the step where I modify the etcd.yaml file, I ran into the exact same error, so the expected solution to the lab’s final question is not work for me.
Could someone please help? I’m not certain why this error would be occurring.
I don’t know if it’s related or not, but when I checked the /etc/systemd/system folder, there didn’t seem to be a kube-apiserver service.