i was following the repo instruction-
but when i run -
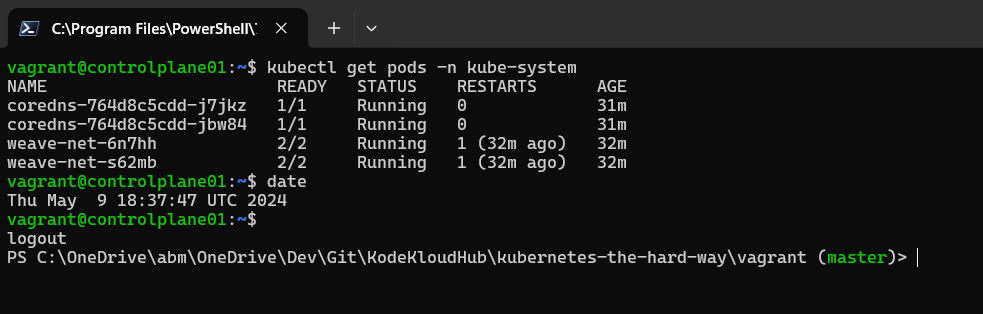
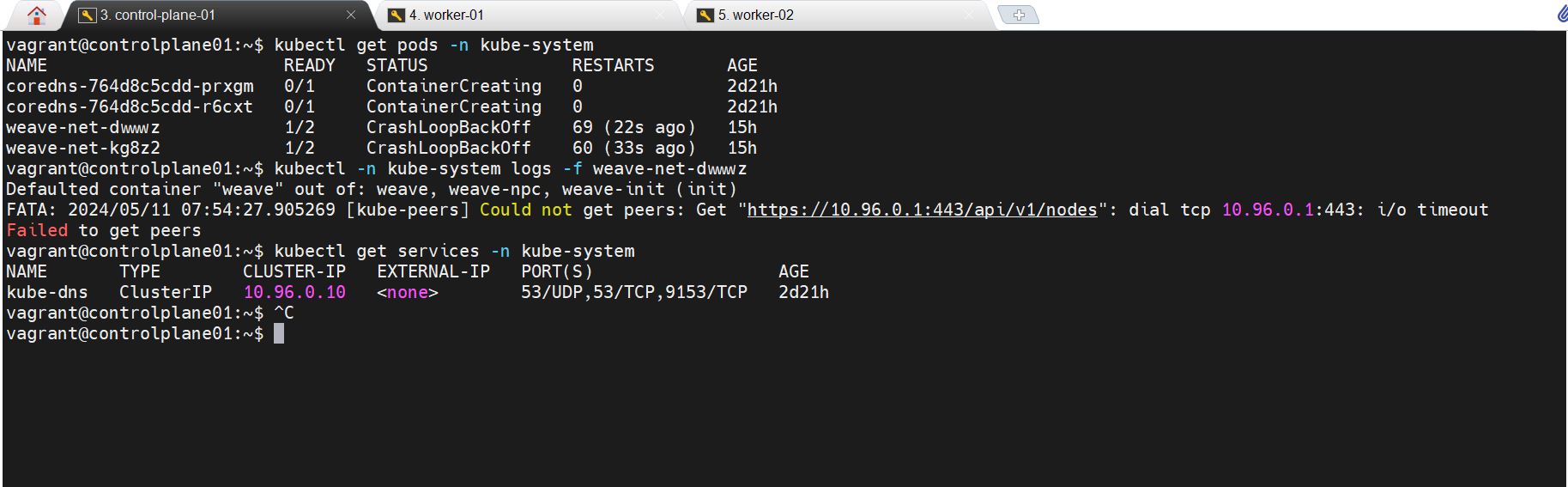
kubectl get pods -n kube-system
i got the below issue
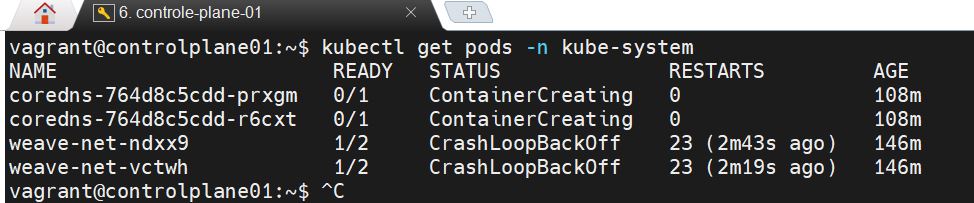
if i run -
kubectl describe pods -n kube-system weave-net-ndxx9
i got the below log:
Name: weave-net-ndxx9
Namespace: kube-system
Priority: 2000001000
Priority Class Name: system-node-critical
Service Account: weave-net
Node: node01/192.168.56.21
Start Time: Wed, 08 May 2024 09:22:20 +0000
Labels: controller-revision-hash=854f95d46f
name=weave-net
pod-template-generation=1
Annotations:
Status: Running
IP: 192.168.56.21
IPs:
IP: 192.168.56.21
Controlled By: DaemonSet/weave-net
Init Containers:
weave-init:
Container ID: containerd://121f26f3f4626c24cd2e60fddda9fe71578ddfeaedbd1a2bef662230377fbb84
Image: weaveworks weave-kube:2.8.1
Image ID: weaveworks/weave-kube@sha256:d797338e7beb17222e10757b71400d8471bdbd9be13b5da38ce2ebf597fb4e63
Port:
Host Port:
Command:
/home/weave/init.sh
State: Terminated
Reason: Completed
Exit Code: 0
Started: Wed, 08 May 2024 11:37:09 +0000
Finished: Wed, 08 May 2024 11:37:10 +0000
Ready: True
Restart Count: 0
Environment:
Mounts:
/host/etc from cni-conf (rw)
/host/home from cni-bin2 (rw)
/host/opt from cni-bin (rw)
/lib/modules from lib-modules (rw)
/run/xtables.lock from xtables-lock (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-wmkbl (ro)
Containers:
weave:
Container ID: d2d0493edb74d75be984ac5042759153607f9304fddee1372423cb0364dec525
Image: weaveworks weave-kube:2.8.1
Image ID: weaveworks weave-kube@sha256:d797338e7beb17222e10757b71400d8471bdbd9be13b5da38ce2ebf597fb4e63
Port:
Host Port:
Command:
/home/weave/launch.sh
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Error
Exit Code: 1
Started: Wed, 08 May 2024 11:51:05 +0000
Finished: Wed, 08 May 2024 11:51:35 +0000
Ready: False
Restart Count: 23
Requests:
cpu: 50m
Readiness: http-get 127.0.0.1:6784/status delay=0s timeout=1s period=10s #success=1 #failure=3
Environment:
INIT_CONTAINER: true
HOSTNAME: (v1:spec.nodeName)
Mounts:
/host/etc/machine-id from cni-machine-id (ro)
/host/var/lib/dbus from dbus (ro)
/run/xtables.lock from xtables-lock (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-wmkbl (ro)
/weavedb from weavedb (rw)
weave-npc:
Container ID: containerd://13b85aefd80533d7ce0ec21c0ed290a766564a695b2f5b70fd7e7faf596fd4aa
Image: weaveworks weave-npc:2.8.1
Image ID: docker.io/weaveworks/weave-npc@sha256:38d3e30a97a2260558f8deb0fc4c079442f7347f27c86660dbfc8ca91674f14c
Port:
Host Port:
State: Running
Started: Wed, 08 May 2024 11:37:11 +0000
Last State: Terminated
Reason: Unknown
Exit Code: 255
Started: Wed, 08 May 2024 09:22:59 +0000
Finished: Wed, 08 May 2024 10:57:55 +0000
Ready: True
Restart Count: 1
Requests:
cpu: 50m
Environment:
HOSTNAME: (v1:spec.nodeName)
Mounts:
/run/xtables.lock from xtables-lock (rw)
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-wmkbl (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
weavedb:
Type: HostPath (bare host directory volume)
Path: /var/lib/weave
HostPathType:
cni-bin:
Type: HostPath (bare host directory volume)
Path: /opt
HostPathType:
cni-bin2:
Type: HostPath (bare host directory volume)
Path: /home
HostPathType:
cni-conf:
Type: HostPath (bare host directory volume)
Path: /etc
HostPathType:
cni-machine-id:
Type: HostPath (bare host directory volume)
Path: /etc/machine-id
HostPathType:
dbus:
Type: HostPath (bare host directory volume)
Path: /var/lib/dbus
HostPathType:
lib-modules:
Type: HostPath (bare host directory volume)
Path: /lib/modules
HostPathType:
xtables-lock:
Type: HostPath (bare host directory volume)
Path: /run/xtables.lock
HostPathType: FileOrCreate
kube-api-access-wmkbl:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional:
DownwardAPI: true
QoS Class: Burstable
Node-Selectors:
Tolerations: :NoSchedule op=Exists
:NoExecute op=Exists
node.kubernetes…io disk-pressure:NoSchedule op=Exists
node.kubernetes…io memory-pressure:NoSchedule op=Exists
node.kubernetes…io network-unavailable:NoSchedule op=Exists
node.kubernetes…not-ready:NoExecute op=Exists
node.kubernetes…pid-pressure:NoSchedule op=Exists
node.kubernetes…unreachable:NoExecute op=Exists
node.kubernetes…unschedulable:NoSchedule op=Exists
Events:
Type Reason Age From Message
Warning Unhealthy 90m (x80 over 149m) kubelet Readiness probe failed: Get “127.0.0.1:6784/status”: dial tcp 127.0.0.1:6784: connect: connection refused
Warning BackOff 85m (x260 over 148m) kubelet Back-off restarting failed container weave in pod weave-net-ndxx9_kube-system(35033da2-7bd1-4c28-8ded-bb336f93258c)
Normal SandboxChanged 15m kubelet Pod sandbox changed, it will be killed and re-created.
Warning Failed 15m (x4 over 15m) kubelet Error: services have not yet been read at least once, cannot construct envvars
Normal Started 15m kubelet Started container weave-init
Normal Created 15m kubelet Created container weave-init
Normal Pulled 15m (x5 over 15m) kubelet Container image “weaveworks/weave-kube:2.8.1” already present on machine
Normal Created 15m kubelet Created container weave
Normal Started 15m kubelet Started container weave
Normal Pulled 15m kubelet Container image “weaveworks/weave-npc:2.8.1” already present on machine
Normal Created 15m kubelet Created container weave-npc
Normal Started 15m kubelet Started container weave-npc
Warning Unhealthy 15m (x5 over 15m) kubelet Readiness probe failed: Get “127.0.0.1:6784/status”: dial tcp 127.0.0.1:6784: connect: connection refused
Normal Pulled 14m (x2 over 15m) kubelet Container image “weaveworks/weave-kube:2.8.1” already present on machine
Warning BackOff 50s (x53 over 14m) kubelet Back-off restarting failed container weave in pod weave-net-ndxx9_kube-system(35033da2-7bd1-4c28-8ded-bb336f93258c)
anyone can help?