Sorry for my English. Here is the Bard version:
Analysis of the lab environment
The lab environment has two worker nodes, node01 and node02, and the IPALLOC_RANGE on Weave is set to 10.50.0.0/16. The clusterCIDR on kube-proxy is set to 10.244.0.0/16. This is a mismatch, as the clusterCIDR must match the IPALLOC_RANGE given to Weave Net.
Impact of the mismatch on SNAT
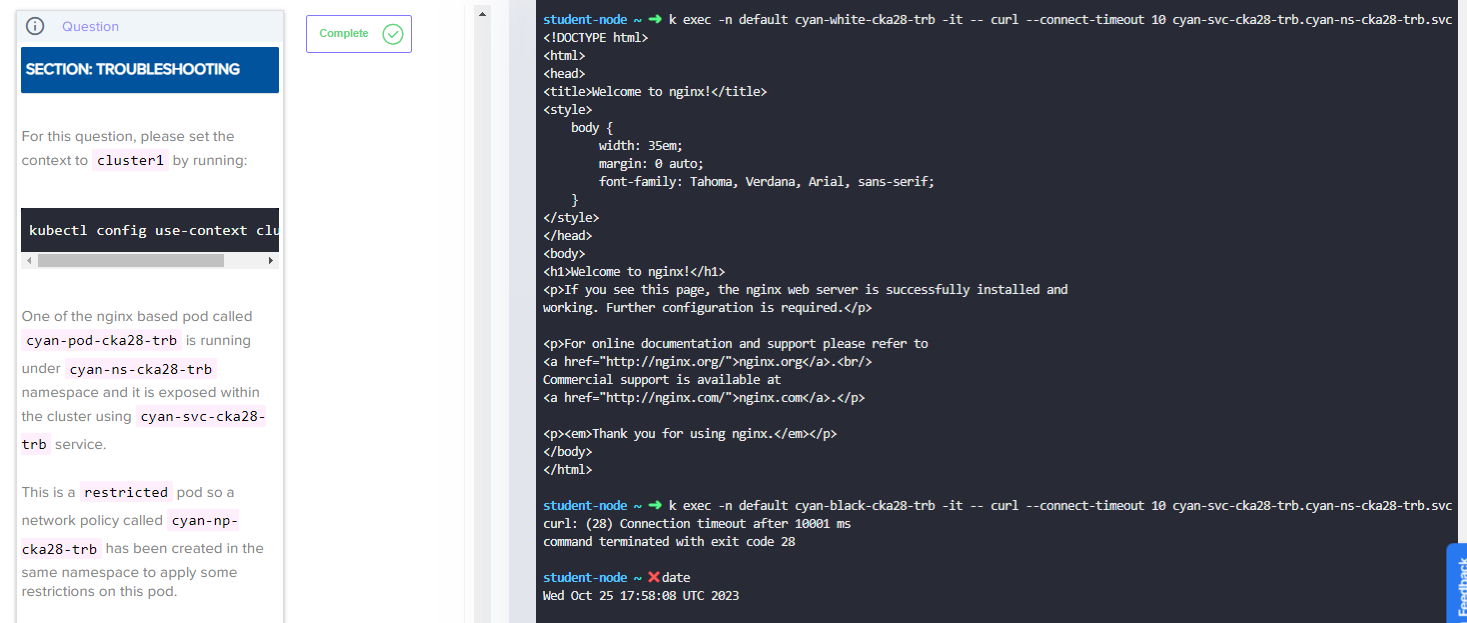
If a pod of white or black stays on the same node as the cyan-pod-cka28-trb, SNAT does not happen. However, if the pods are on different nodes, SNAT will happen and the source IP will be changed to the node IP. This can be seen in the iptables rule:
-A KUBE-SVC-A53YBJOHBLWETSHT ! -s 10.244.0.0/16 -d 10.100.64.59/32 -p tcp -m comment --comment “cyan-ns-cka28-trb/cyan-svc-cka28-trb cluster IP” -m tcp --dport 80 -j KUBE-MARK-MASQ
This rule matches all TCP packets on port 80 that are not from the 10.244.0.0/16 network and are destined for the 10.100.64.59/32 network. The KUBE-MARK-MASQ target marks the packets for SNAT, which means that the source IP will be changed to the node IP.
Impact of SNAT on network policies
If SNAT happens, network policies will not work as expected. This is because network policies are based on pod IPs, not node IPs. If a pod’s IP is changed to the node IP, the network policy will no longer be able to match the pod.
Recommendations
To fix the problem, you need to make sure that the clusterCIDR on kube-proxy matches the IPALLOC_RANGE given to Weave Net. Once you have done this, SNAT will no longer happen and network policies will work as expected.
Here are the steps to fix the problem:
- Edit the kube-proxy configuration file and set the
cluster-cidr flag to match the IPALLOC_RANGE given to Weave Net.
- Restart kube-proxy.
kubectl rollout restart daemonset -n kube-system kube-proxy