Find the node across all clusters that consumes the most CPU and store the result to the file /opt/high_cpu_node in the following format cluster_name,node_name .
The node could be in any clusters that are currently configured on the student-node .Lab- CKA Mock Exam 3 - KodeKloud
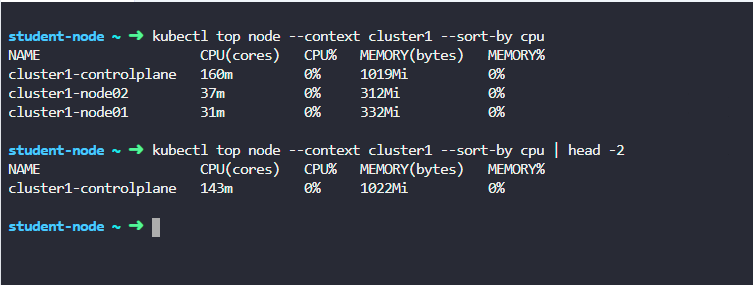
Troubleshooting : I used the below command
But its giving wrong answer. Also excluding --no-headers will make any impact or not. Since i want headers so i wrote head -2.
mmkmou
May 24, 2023, 9:09pm
#2
Hi @uzmashafi061 ,
Please refer to the response and adapt the command to CPU
Please note that you need to run the command on all cluster and compare the result
Regard
one more doubt here, is excluding --no-headers in the command make any impact or not?
mmkmou
May 30, 2023, 9:58am
#4
Hi @uzmashafi061 ,
--no-headers will remove the first line with the column name, for this exercise no real impact he’ll help you see the name of the column.
You have to use head -2 on this case
https://man7.org/linux/man-pages/man1/head.1.html