



Highlights
- Learn Kubernetes architecture explained step by step - from control plane to Pods.
- Understand the difference between master node vs worker node and their unique roles.
- Explore how Kubernetes components like API Server, Scheduler, and Kubelet communicate.
- Discover how Kubernetes works to deploy, scale, and self-heal applications automatically.
- Visualize the entire Kubernetes cluster architecture - nodes, Pods, and communication flow.
- Master the fundamentals of container orchestration through KodeKloud’s free Kubernetes labs.
- No setup, no stress - learn interactively with real environments and visual diagrams.
- Build confidence to move from beginner to production-level Kubernetes management.
Introduction: Understanding the Heart of Kubernetes
When people talk about Kubernetes, they often describe it as a “container orchestration system.” But what truly makes Kubernetes so powerful is its architecture - a carefully designed structure that allows it to manage thousands of containers, balance workloads, and keep applications running smoothly across any environment.
To understand how Kubernetes works, you first need to understand how it’s built. The Kubernetes architecture is made up of multiple components that work together - just like a living system with a brain, hands, and nerves. Each component has a defined purpose: some make decisions, some execute them, and others maintain order when things go wrong.
At its core, Kubernetes follows a cluster-based architecture, where every deployment consists of a control plane (often referred to as the master node) and a set of worker nodes. This design allows Kubernetes to distribute workloads efficiently and recover from failures automatically, ensuring high availability for your applications.
In this guide, we’ll break down Kubernetes architecture explained - from nodes and pods to the control plane and cluster structure. You’ll learn how these pieces fit together, how they communicate, and how Kubernetes turns a group of machines into one intelligent, self-managing system.
By the end, you’ll not only understand what each component does, but also why this architecture has made Kubernetes the de facto standard for container orchestration in modern DevOps and cloud environments.
What Is Kubernetes Architecture? (Big Picture Overview)
Before diving into each part of the system, let’s first understand what we mean by Kubernetes architecture.
In simple terms, Kubernetes architecture is the design and structure that defines how Kubernetes operates as a distributed system. It’s what allows multiple machines to work together as a single, unified environment that runs, manages, and scales containerized applications automatically.
At the highest level, Kubernetes cluster architecture consists of two main layers:
- The Control Plane (Master Node) - This is the brain of Kubernetes. It makes global decisions, such as scheduling applications, monitoring system health, and managing cluster state.
- The Worker Nodes - These are the hands of Kubernetes. They run your actual workloads - the containers and Pods that power your applications.
Together, these two layers form what’s known as a Kubernetes cluster - the complete environment where applications live and communicate. Each node, whether it’s a master or a worker, has its own role, responsibilities, and components. The control plane directs and coordinates, while worker nodes execute those instructions.
The strength of Kubernetes cluster architecture lies in its decentralized and resilient design. Even if a node fails, Kubernetes automatically shifts workloads to healthy nodes, ensuring that your system continues running smoothly. This is what makes Kubernetes the foundation of reliable and self-healing container orchestration.
When people search for Kubernetes architecture explained, they’re really looking to understand this concept:
How multiple machines - physical or virtual - can act together as one intelligent system to deploy and manage containers seamlessly.
In the upcoming sections, we’ll explore each layer of this architecture in detail. We’ll start with the Kubernetes cluster - the foundation that ties everything together - before moving into the specific components that make it work.
The Kubernetes Cluster - The Foundation
A Kubernetes cluster is the heart of the entire system. It’s the environment where every part of Kubernetes comes together to manage, schedule, and run containerized applications effectively.
In the simplest form, a cluster is a collection of nodes - one or more control plane nodes that manage the system and multiple worker nodes that run your workloads. Together, these nodes create a unified platform that can host applications at any scale.
This is what makes Kubernetes architecture so powerful: you’re not managing a single machine anymore; you’re managing an entire cluster of machines that behave as one logical system.
How the Cluster Works
When you deploy an application on Kubernetes, you don’t tell it which machine to use. You simply define your desired state - for example, “run three replicas of this web app.” The control plane (which we’ll explore next) takes that instruction, decides where those replicas should run, and assigns them to available worker nodes.
The nodes then launch containers inside Pods, manage networking, and ensure everything stays running as expected. If a node goes down, the control plane detects the issue and reschedules those Pods on healthy nodes - this is the self-healing capability at the core of how Kubernetes works.
Key Traits of a Kubernetes Cluster
- Distributed by Design: The cluster can span multiple machines, regions, or even clouds.
- Resilient and Fault-Tolerant: Node failures don’t cause downtime - Kubernetes automatically recovers workloads.
- Scalable: You can add or remove nodes easily, allowing your infrastructure to grow with your needs.
- Declarative Management: Everything in Kubernetes is defined as code, ensuring predictable and repeatable deployments.
Why the Cluster Matters
The Kubernetes cluster architecture is what turns simple container hosting into a full-scale orchestration platform. Without the cluster model, Kubernetes wouldn’t be able to achieve its most powerful capabilities - automatic scaling, load distribution, and high availability.
Every feature that makes Kubernetes special - from Pods and Services to the control plane and nodes - depends on this cluster foundation.
In short, a Kubernetes cluster is like a team of coordinated machines working together toward one goal: to run your applications reliably, no matter what happens underneath.
Control Plane Components - The Brain of Kubernetes
Every Kubernetes cluster has a control plane, often called the brain of Kubernetes. This is where all the major decisions happen - scheduling workloads, monitoring health, and maintaining the desired state of your applications.
If the worker nodes are the hands of Kubernetes, the control plane is the part that plans, coordinates, and ensures everything runs exactly as intended.
The Kubernetes control plane runs several key components that work together to manage the cluster. Let’s look at each one and understand its role in keeping the system healthy and responsive.
1. API Server - The Front Door of the Cluster
The Kubernetes API Server is the entry point to the entire cluster. Every request - whether from a user, the kubectl command-line tool, or internal components - goes through the API Server first.
It validates and processes these requests before updating the cluster’s state in the database (etcd). You can think of it as the central hub that every other component depends on.
In short: The API Server is how you talk to Kubernetes - and how Kubernetes talks to itself.
2. etcd - The Cluster’s Memory
etcd is a highly reliable, key-value database that stores all the cluster data. It keeps the official record of what’s running, what should be running, and the configuration of every Kubernetes component.
If the API Server is the brain’s logic center, etcd is its long-term memory - without it, Kubernetes wouldn’t know the current state of the cluster.
Tip: etcd stores everything from Pod definitions to node health, making it the single source of truth for Kubernetes architecture.
3. Scheduler - The Decision Maker
When you create a new Pod, the Kubernetes Scheduler decides where it should run. It checks all available worker nodes and matches each Pod to the one with the right resources, labels, and constraints.
This ensures that workloads are evenly distributed across the cluster and that no single node gets overloaded. The Scheduler’s smart decision-making is one of the key reasons how Kubernetes works efficiently in large environments.
Think of it as the project manager assigning tasks to the best team members (nodes).
4. Controller Manager - The Cluster’s Automation Engine
The Controller Manager continuously monitors the state of the cluster and takes corrective actions whenever something drifts from the desired state.
For example:
- If a Pod crashes, it triggers a new one.
- If a node goes down, it reschedules workloads elsewhere.
- If replicas are missing, it creates them automatically.
The Controller Manager acts like an autopilot system, constantly ensuring that what you defined as your desired configuration matches the actual running environment.
How These Components Work Together
Here’s how the Kubernetes control plane keeps the cluster stable:
- The user sends a request (for example, to create a Deployment).
- The API Server receives it and updates etcd with the desired state.
- The Scheduler picks the best node for new Pods.
- The Controller Manager ensures everything stays as defined.
This continuous feedback loop keeps Kubernetes clusters self-healing, automated, and scalable, no matter how complex your infrastructure grows.
In essence, the control plane is what transforms Kubernetes from a collection of nodes into a smart, self-managing orchestration platform. Without it, Kubernetes would just be a group of disconnected systems.
Worker Node Components - The Hands of Kubernetes
If the control plane is the brain of Kubernetes, the worker nodes are its hands - they perform the actual work of running your containers and keeping your applications alive.
Each node in a Kubernetes cluster is a separate machine (physical or virtual) that hosts the Pods where containers run. The control plane gives the orders, but it’s the worker nodes that execute them.
These nodes include several essential Kubernetes components that make this communication and execution possible.
1. Kubelet - The Node’s Local Agent
The kubelet is a lightweight agent that runs on every worker node. It’s responsible for making sure the containers assigned to that node are running exactly as instructed by the control plane.
Here’s what it does:
- Talks to the API Server to receive Pod specifications.
- Starts and monitors the containers for each Pod.
- Reports back the node’s health and status to the control plane.
If a Pod fails, the kubelet ensures it’s restarted or replaced according to the defined rules.
Think of the kubelet as a personal assistant on each node — always checking that every assigned task is running properly.
2. Kube-Proxy - The Network Manager
The kube-proxy handles all network communication inside the cluster. It manages traffic routing to ensure that requests reach the correct Pods, no matter where they’re running.
Its key responsibilities include:
- Maintaining network rules on each node.
- Handling load balancing for services.
- Managing communication between Pods across nodes.
Without kube-proxy, the distributed nature of Kubernetes networking would make communication between Pods and Services nearly impossible.
You can think of kube-proxy as the cluster’s air traffic controller - guiding data packets safely to their destinations.
3. Container Runtime - The Engine Running the Containers
The container runtime is the underlying software that actually runs the containers inside Pods. Kubernetes supports multiple runtimes, including containerd and CRI-O, which are now preferred over the legacy Docker runtime.
The runtime is what pulls container images, starts containers, and manages their lifecycles based on kubelet’s instructions.
In short, the runtime does the heavy lifting, while the kubelet and kube-proxy ensure everything runs and communicates correctly.
How Worker Nodes Fit into Kubernetes Architecture
In the broader Kubernetes architecture explained, worker nodes act as the execution layer. They don’t make decisions - they carry them out. The control plane decides what needs to happen, and the worker nodes make it happen by running the containers and maintaining network connectivity.
This division of roles between master node vs worker node ensures that Kubernetes clusters remain scalable and reliable. If one worker node fails, another one automatically picks up the load, keeping your applications available.
Why Worker Nodes Matter
The worker node layer is where all real workloads live. Every web app, database, or background service you deploy in Kubernetes ultimately runs on these nodes. They form the physical and logical base that turns instructions from the control plane into running containers your users can access.
In essence, Kubernetes nodes are what transform infrastructure into action.
Pods - The Smallest Unit of Deployment
Inside every Kubernetes cluster, all the action happens within Pods. A Pod is the smallest deployable unit in Kubernetes architecture - the place where your application’s containers actually run.
When the control plane schedules workloads, it doesn’t place containers directly onto nodes. Instead, it places Pods - which then contain one or more containers that share the same network and storage resources.
What Is a Pod?
A Pod represents a single instance of a running process in your cluster. Most of the time, a Pod runs just one container, but it can also run multiple containers that need to work together closely.
For example, a web server container and a helper container that updates static files might run inside the same Pod - sharing the same lifecycle, IP address, and storage volume.
You can think of a Pod as a small “wrapper” that defines how one or more containers should run and interact within a node.
How Pods Work
When you deploy an application, Kubernetes:
- Accepts your desired configuration (like number of replicas or resource limits).
- The Scheduler assigns Pods to appropriate worker nodes.
- The kubelet on each node creates and monitors those Pods.
- The container runtime runs the containers inside each Pod.
If a Pod fails or a node goes offline, the Controller Manager ensures that a new Pod is created elsewhere, maintaining your desired state.
This system is what makes Kubernetes self-healing - applications recover automatically, without human intervention.
Pods and Networking
Each Pod in Kubernetes gets its own IP address within the cluster. Containers inside the same Pod can communicate with each other directly using localhost, while communication between Pods happens through Services (which we’ll explore in later blogs).
This design simplifies how Kubernetes works internally - treating each Pod as an isolated, self-contained environment.
Pods, Nodes, and the Bigger Picture
Every Pod runs on a Kubernetes node, and the control plane continuously monitors them through the kubelet. Pods are not permanent; they’re created, destroyed, and replaced dynamically based on your application’s configuration.
That’s why you never interact with Pods directly in most cases - instead, you use higher-level Kubernetes componentslike Deployments or ReplicaSets, which manage Pods automatically.
In short: You define what you want to run; Kubernetes decides how many Pods to create, where to place them, and how to keep them alive.
Why Pods Matter
Pods are at the heart of everything Kubernetes does. They’re the building blocks that connect the control plane’s intelligence with the nodes’ execution power. Whether you’re running a web server, database, or API, it all lives inside a Pod.
Understanding Pods is the first step toward mastering Kubernetes architecture explained - because every other component revolves around them.
How Kubernetes Works - Step-by-Step Workflow
Now that we’ve explored the Kubernetes components individually - from the control plane to the worker nodes and Pods - it’s time to see how they all come together in action.
This is where the real power of Kubernetes architecture becomes clear. Everything in Kubernetes revolves around a simple idea: the desired state. You tell Kubernetes what your application should look like - and it continuously works behind the scenes to make sure that state is achieved and maintained.
Let’s walk through the process step by step.
Step 1: Defining the Desired State
You start by describing your application in a YAML configuration file.
For example, you might say:
“Run three replicas of this Nginx web server.”
This file defines what you want Kubernetes to do - not how to do it. That’s the core of how Kubernetes works: it’s declarative, not procedural.
You then apply the configuration using the kubectl apply -f command. This request goes straight to the API Server, the entry point of the cluster.
Step 2: API Server Processes the Request
The Kubernetes API Server receives the request and validates it. Once confirmed, it records your desired state in etcd, the cluster’s key-value database. At this point, your desired configuration officially becomes part of the cluster’s state.
etcd acts as the memory of the cluster, storing what should be running at all times.
Step 3: Scheduler Assigns Pods to Nodes
Next, the Scheduler scans the available worker nodes and decides where to place the new Pods. It considers:
- CPU and memory availability
- Node labels and affinities
- Resource constraints and taints
Once the Scheduler selects the best nodes, it instructs the kubelet on those nodes to create the required Pods.
Step 4: Kubelet Creates and Monitors Pods
On each selected worker node, the kubelet receives Pod specifications and interacts with the container runtime (like containerd or CRI-O) to start the containers. It constantly checks that these Pods are running correctly and reports back to the control plane.
If a Pod crashes or becomes unresponsive, the kubelet immediately notifies the Controller Manager, which triggers the creation of a replacement Pod elsewhere.
This feedback loop is what gives Kubernetes its self-healing power.
Step 5: Kube-Proxy Manages Networking
The kube-proxy ensures that network traffic is properly routed to the correct Pods. It maintains load-balancing rules and handles connections between different Pods and Services across nodes.
This makes the system feel like a unified network, even though it’s distributed across multiple machines.
From a user’s perspective, it doesn’t matter where your Pod runs - it’s always reachable.
Step 6: Controller Manager Ensures Desired State
Meanwhile, the Controller Manager constantly compares the desired state (stored in etcd) with the current state(reported by nodes). If there’s any difference - such as a missing Pod, failed node, or resource imbalance - the controller takes corrective action automatically.
This continuous reconciliation process is the heartbeat of Kubernetes architecture explained - keeping your cluster stable and predictable.
Step 7: Scaling, Updates, and Maintenance
Once everything is running, you can scale your application by simply changing the number of replicas in your configuration. Kubernetes automatically adds or removes Pods across nodes to match your new state.
When you roll out an update, Kubernetes performs a rolling update, replacing old Pods with new ones without downtime. If something goes wrong, you can rollback instantly to a previous version - all controlled through the same declarative model.
In Short: How Kubernetes Works
| Stage | Component Involved | Function |
|---|---|---|
| Define desired state | API Server + etcd | Store what you want to run |
| Schedule workloads | Scheduler | Decide where Pods should run |
| Execute workloads | Kubelet + Runtime | Run and monitor containers |
| Manage networking | Kube-Proxy | Route traffic to Pods |
| Maintain stability | Controller Manager | Keep cluster in sync |
Together, these steps make Kubernetes self-managing, fault-tolerant, and scalable - a system that continuously keeps your applications running exactly as you intended.
Master Node vs Worker Node - Key Differences
In a Kubernetes cluster, not all nodes serve the same purpose. Every cluster is divided into two main categories of nodes - master nodes and worker nodes - each playing a unique role in keeping the system balanced, resilient, and automated.
Understanding this distinction is essential for anyone learning Kubernetes architecture explained, as it defines how the entire cluster functions as one coordinated system.
Master Node - The Control Center
The master node (also known as the control plane) is responsible for managing and orchestrating everything inside the cluster. It doesn’t run application workloads itself - instead, it ensures the right workloads are scheduled, healthy, and properly distributed across worker nodes.
Key responsibilities include:
- Maintaining the cluster state through etcd
- Managing workloads using Controller Manager and Scheduler
- Handling all communication via the API Server
- Making global decisions like scaling, recovery, and updates
Essentially, the master node acts as the decision-maker. It sees the entire cluster, understands what should be running, and makes sure reality matches that vision.
Think of the master node as a project manager - it doesn’t do the work itself but ensures everything is on track.
Worker Node - The Execution Layer
The worker nodes are where your applications actually live. They’re responsible for running Pods, maintaining container health, and managing local networking and storage.
Each worker node runs a few critical components:
- Kubelet: Ensures containers are running as instructed
- Kube-Proxy: Handles networking and routing
- Container Runtime: Runs the actual containers (e.g., containerd, CRI-O)
Worker nodes report their status to the control plane and execute whatever tasks are assigned. If a node fails, Kubernetes automatically shifts workloads to another available worker node, keeping the system resilient.
You can think of worker nodes as the engineers - doing the real work based on the master node’s plan.
Master Node vs Worker Node - Comparison Table
| Feature / Role | Master Node (Control Plane) | Worker Node |
|---|---|---|
| Primary Function | Manages the cluster and makes decisions | Runs workloads and executes containers |
| Key Components | API Server, etcd, Scheduler, Controller Manager | Kubelet, Kube-Proxy, Container Runtime |
| Workload Execution | No (management only) | Yes (Pods and containers) |
| State Management | Maintains desired and actual state of cluster | Reports local state to control plane |
| Failure Recovery | Restores workloads on healthy nodes | Recreates or moves Pods when needed |
| Scalability Role | Manages scaling strategy | Hosts scaled workloads |
How They Work Together
- The master node defines what should happen.
- The worker nodes execute how it happens.
This separation ensures that the Kubernetes cluster architecture remains both centralized in control and distributed in execution. If one worker node fails, others keep running.
If a master node goes down, a backup control plane can take over - ensuring continuous availability.
Why This Design Matters
The division between master node vs worker node allows Kubernetes to scale infinitely while maintaining consistency. You can add new worker nodes to handle more workloads or replicate control planes for redundancy - all without disrupting existing applications.
This architecture is what makes Kubernetes flexible, fault-tolerant, and perfectly suited for cloud-native environments.
Visualizing Kubernetes Architecture (KodeKloud Tip)
Understanding Kubernetes through theory is one thing - but truly mastering it requires seeing how the system behaves in real time. Kubernetes architecture is highly visual by nature: nodes, pods, and clusters constantly communicating, scaling, and recovering in harmony.
That’s why one of the best ways to learn Kubernetes architecture explained is through visualization and hands-on exploration.
Visualizing the Cluster Structure
A Kubernetes cluster architecture can be visualized as three interconnected layers:
- The Control Plane (Master Node) - the decision-making layer that manages the entire system.
- The Worker Nodes - where Pods actually run, each containing kubelet, kube-proxy, and the container runtime.
- The Pods - the smallest execution units hosting your containers.
These layers communicate continuously through the API Server, ensuring that workloads are scheduled correctly, the system’s state is monitored, and everything remains synchronized.
Once you see these interactions in a live environment, the logic of Kubernetes becomes far easier to grasp.
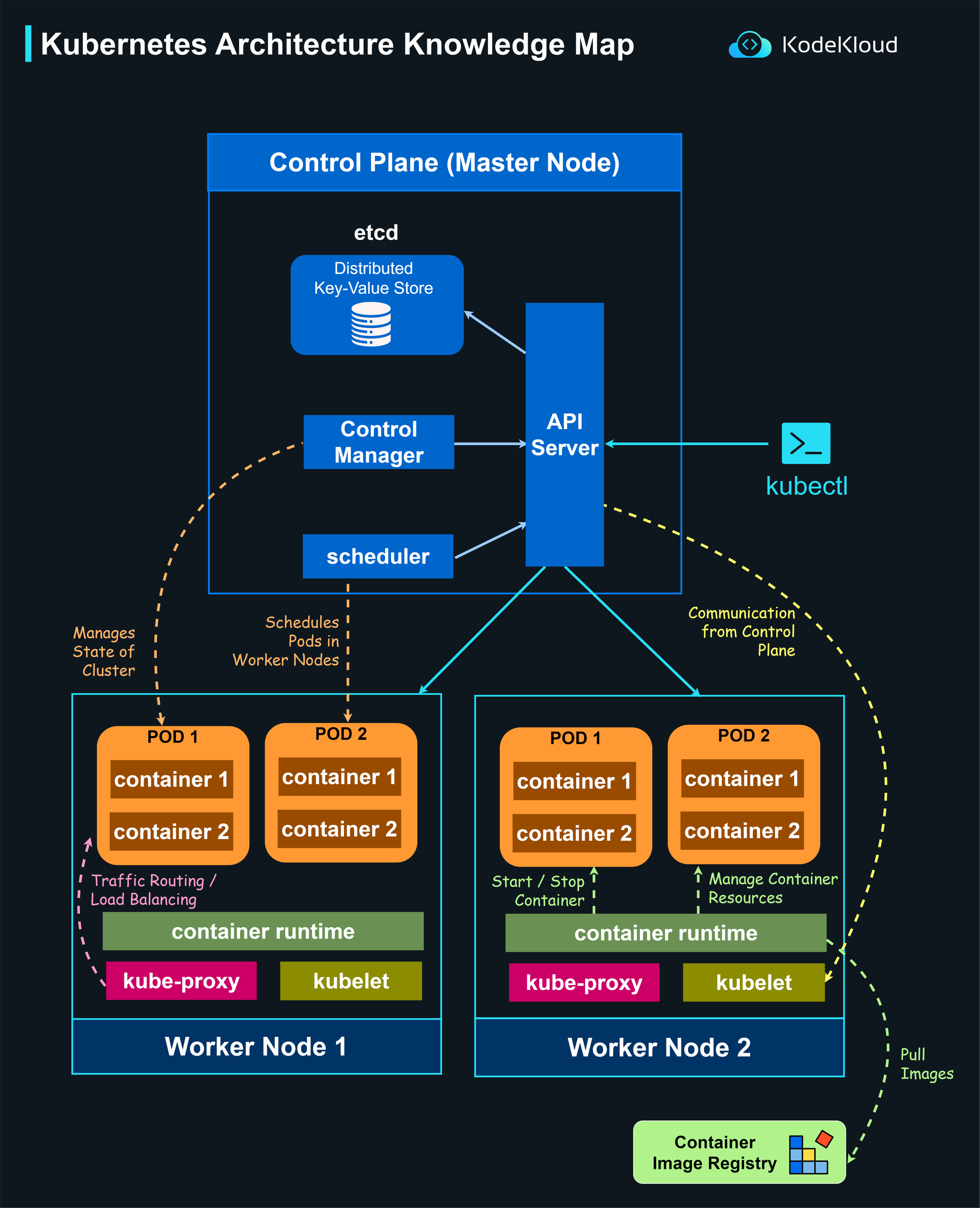
Learn by Seeing and Doing
If you prefer learning visually and interactively, KodeKloud provides some of the best resources available to truly experience how Kubernetes works in action:
- Kubernetes Labs - Hands-On
Explore how control plane components, nodes, and Pods work together and communicate.
- KodeKloud YouTube Channel
Watch detailed breakdowns of complex topics like cluster communication, kube-proxy networking, and container orchestration - explained with visuals and examples.

- Kubernetes Made Easy eBook
Includes detailed diagrams showing the relationship between Kubernetes components, from API Server to kubelet. Perfect for quick revision and conceptual clarity.
- 🧾 Open DevOps 101 Repository
A growing collection of infographics and visual explainers covering topics like Pods, Services, and the Kubernetes control plane - all freely accessible.
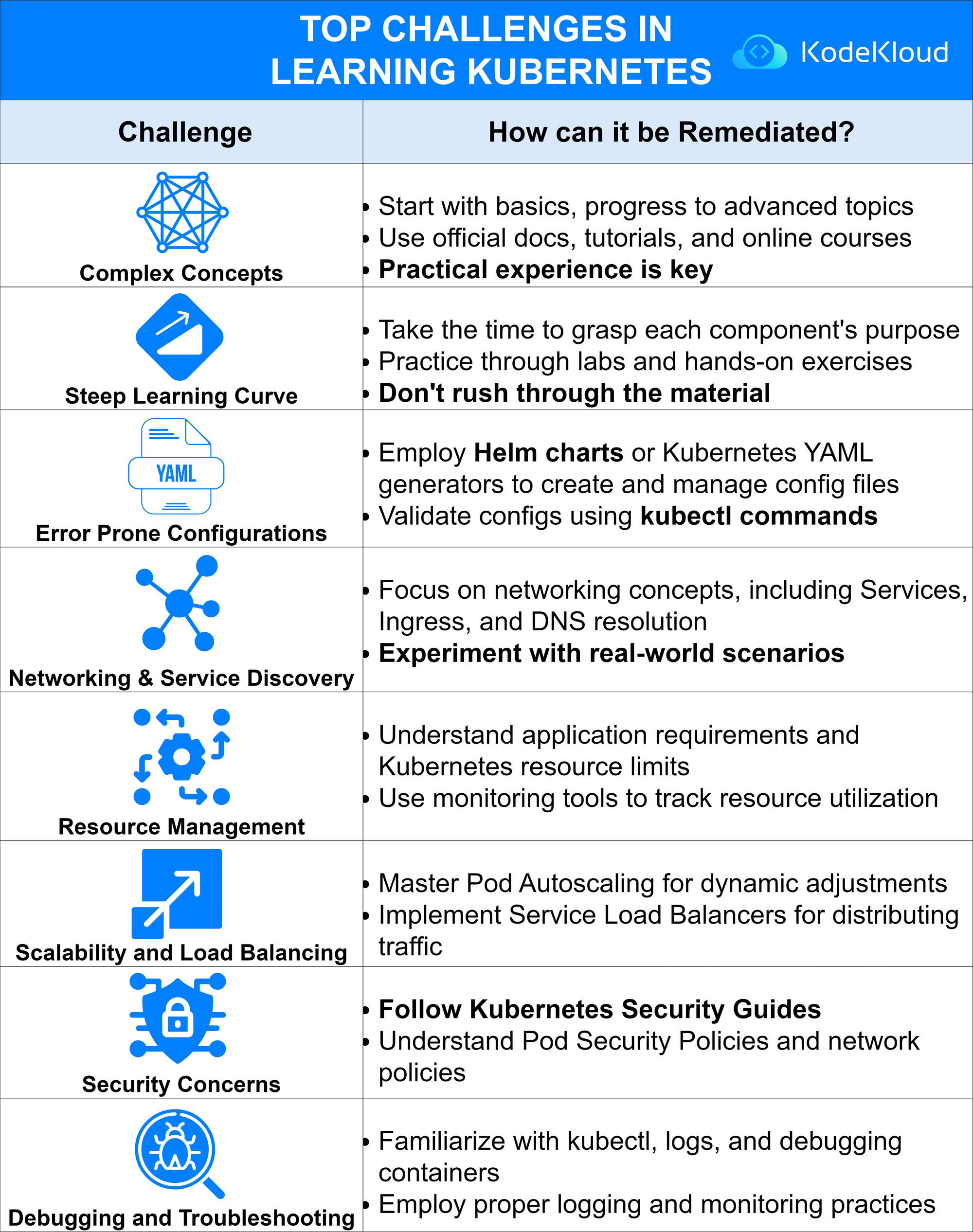
FAQs
Do I need Docker to use Kubernetes?
No - modern Kubernetes doesn’t depend on Docker.
It uses container runtimes like containerd or CRI-O, which handle container execution more efficiently. Docker images still work, but Kubernetes doesn’t need the Docker engine anymore.
How much memory or CPU do I need to run a local Kubernetes cluster?
For tools like Minikube or Kind, 2 CPUs and 4 GB RAM are enough to start experimenting. But for a smoother experience (and real-world practice), KodeKloud’s labs give you cloud-powered clusters with zero local setup.
Is Kubernetes used only with cloud providers like AWS or GCP?
Not at all.
You can run Kubernetes on-premises, on your laptop, or in any cloud. Cloud providers just make scaling and managing clusters easier, but Kubernetes itself is completely platform-agnostic.
How do companies monitor what’s happening inside Kubernetes?
They use observability tools like Prometheus, Grafana, and Lens to track cluster health, resource usage, and Pod logs. KodeKloud’s advanced labs even simulate these setups so you can see monitoring in action.
Can I use Kubernetes for non-containerized applications?
No - Kubernetes is designed specifically for containerized workloads.
If your app isn’t containerized yet, start by learning Docker and packaging your app - then move to Kubernetes for orchestration.













Discussion